
Daqi Xu
College of Management Engineering, Anhui Polytechnic University, Beijing Middle Road, Wuhu, 241000, Peoples� Republic of China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 5 | Page No.: 637-641







ABSTRACT
This study described the degree of influencing brand degree preference in different consumers through linguistic term, operated linguistic assessment information by applying evidential reasoning algorithm and combining the operator of dyadic semanteme, concluded different brand language evaluation value based on dyadic semanteme then measured and sorted different brand preference with the dyadic semanteme properties. The consumer brand preference ranking method under uncertain environment is a scientific solution to various uncertain problems in the consumer brand preference ordering. Finally, an analysis example is given to illustrate the feasibility and affectivity of the method.
PDF Abstract XML References Citation
Received: October 26, 2011;
Accepted: January 07, 2012;
Published: February 22, 2012
How to cite this article
Daqi Xu, 2012. The Research on Sort Method of Consumer’s Brand Preference Under Uncertain Environment. Information Technology Journal, 11: 637-641.
DOI: 10.3923/itj.2012.637.641
URL: https://scialert.net/abstract/?doi=itj.2012.637.641
DOI: 10.3923/itj.2012.637.641
URL: https://scialert.net/abstract/?doi=itj.2012.637.641
INTRODUCTION
The consumer’s brand preference is consumers’ attempt to maintain a relationship with the target brand through a series of behaviors, primarily including allocation of a higher share of wallet to a particular service provider and their engagement in dissemination of the public praise and repeated purchases. Brand preference is not only a kind of behavior process but also a kind of psychological decision evaluation process (Lu and Zhang, 2004). Degree of brand preference is particularly important to consumers’ scientific and reasonable decision-making for a purchase. At the same time, to determine the extent of consumers’ brand preference is especially important to product designers, producers and sellers, based on which correct and effective operation decisions are made (Grimm, 2005; Da and Yingqing, 2005).
Consumers’ brand preference behavior research is conducted mainly from three aspects in existing literature: The first, with reference to the utility maximization principle in economics, assuming that the consumers are informed completely of the various generic property of the brand, all information is to be synthesized, then the utility of each brand is calculated and compared with others’, subsequently, the brand of the biggest overall utility is chosen. MNL model by Swait and Adamowicz (1996) and IPM model by Currim (1982) are the typical of this selection model of utility maximization. The second category simulates customers’ purchase psychology, presuming that consumers have complete knowledge of the various generic property of the brand. Comparing the brands in pairs based on the attribute value to eliminate the inferior, so as to determine the ideal brand for consumers. The binary choice model of Restle (1961) and multiple choice model of EBA by Tversky and Kahneman (1991) are the representatives of the second type; The third type measures multidimensional consumers’ decision-making psychological characteristics upon the presumption that consumers are fully acquainted with various brand generic values and gives the multi-factor model consisting of different psychological characteristics (Walsh et al., 2001). At present, most of both Chinese and foreign marketing researchers widely employ these three models to analyze the market structure, determine the product market, predict consumer’s brand preference and divide consumers into groups (DeSarbo et al., 1994; Eliashberg and Manrai, 1992). Obviously, the above-mentioned types of studies are based on probability theory or the utility function of the brand preference sorted, whether it is based on factual data or expert experience, are built on the basis of certain assumptions (such as the assumption that consumer understood completely to brand various generic attribute value(4the data fully, etc.) to expand the research.
However, when the consumers choose the brand in real life, due to ambiguity of the human mental activities, uncertainties of decision-making environment and absence of decision-making data, the consumers hardly judge information of the brand preference by the accurate data but by language phrases instead. For instance, it is relatively easy to use the information of the language preference such as good, better, bad, worse to evaluate post-sale service of a certain brand (Shiv and Fedorikhin, 1999). As for uncertainty of the consumer’s brand preference, Wu and Pan (2004) and Matsatsinis and Samaras (2000) have done some related research. Their research paper presupposes that attribute values working on brand choice has been given in the form of vague language, namely through the fuzzy semantics into a triangular fuzzy number, then use computational methods such as fuzzy number generalized addition, approximate multiplication and scalar multiplication to determine the consumer brand preference sequence.
However, the decision-making of the consumers’ brand preference is different from that of large projects in that the latter one is characteristic of strict procedures, enough time and money and involvement of some experts in the field in decision-making, while the consumer’s decision-making may occur at any time without participation of experts in the field in most cases. The decision makers may be the consumer himself or the group familiar with him, due to their knowledge background, ability, money and time pressure and the lack of some data, they give their evaluation information of the brand in vague language and more possibly, by the language between two standard language evaluation grades or they are unable to give some attributes of a brand, namely a certain language attribute value is absent. But, Wu and Pan (2004) and Matsatsinis and Samaras (2000) research into the brand preference in language fails to consider one fact that to give the brand appraisal information possibly is situated between two standard language opinion rating or the vacancy situation. At the same time it does not take it into account the effect of different attribute weights on the intrgrited utility of the degree of brand preference. In order to solve many uncertainties in the consumer's brand preference sequence scientifically and effectively, this article applies the evidence inference algorithm, together with dual semantic the related operator, taking family car brand as an example to integrate information of different brand preferences on the uncertain environment and then to carry on the computation on the different degree of brand preference and to do reasonable sorting according to the computations.
THE METHOD OF THE CONSUMER’S BRAND PREFERENCE SEQUENCE
The expression method of confidence level under uncertainty environment: supposes L be a standard language phrase collection, it is a pre-defined ordered set composed of some odd number elements (Herrera and Martinez, 2000). This study considers a set which is made up of 7 element (i.e., standard language phrases), namely L = (L0, L1, L2, L3, L4, L5, L6,) = {worst, worse, bad, common, good, better, best}. For a scheduling problem of the consumer brand preference degree, we suppose that there be M index factors C = {C1, C2, …, CM} which influence consumer brand preference, we use the set W = {ω1, ω2, …, ωM} to express the weight of the index factors and:
there are N consumer brand A = {A1, A2, …, AN}, the decision-makers give rij which is the language evaluation value of Brand Ai relative to the index Cj, Namely obtains language appraisal matrix R = (rij)NxM. Here, rij belongs to a L language opinion rating, either is situated between two language opinion rating or vacancy. Specifically, if the decision-makers give a standard evaluation rating which is the language evaluation value of Brand Ai relative to the index Cj, we mark it with Ls (s = 0, 1, …, T); if the decision-makers gives the language appraisal value is situated between two standard language opinion rating, we mark it with Ls+α, αε(0, 1), its meaning is that the decision-makers gives actually the appraisal information is situated between Ls and Ls+1, its deviation is α which relative to Ls, its deviation is 1-α which relative to Ls+1; if the decision-makers can not give a standard evaluation rating which is the language evaluation value of Brand Ai relative to the index Cj, we mark it with “-” which is expressed vacancy.
Thus, the following is evaluation information belonging to confidence level of the language opinion rating expression (Zhijian and Chao, 2006):
| • | If the decision-makers gives rij the language appraisal value is Ls, then evaluation of the value of Ai brand preference degree relative index Cj belongs to the Ls confidence level is Q (i, j, s) = 1 |
| • | If the decision-makers gives rij the language appraisal value is Ls+α, then evaluation of the value of Ai brand preference degree relative index Cj belongs to the Ls confidence level is Q (i, j, s) = 1-α, belongs to the Ls+1 confidence level is Q (i, j, s+1) = α |
| • | If the decision-makers can not give rij the language appraisal value, namely the decision-makers can not describe that Ai brand preference degree relative index Cj, then evaluation of the value of Ai brand preference degree relative index Cj belongs to the Ls confidence level is Q (i, j, s) = 0 |
Solving the confidence level of the brand under language opinion rating: According to evidence theory related content (Shafer, 1976), evaluation of the value of Ai (i = 1, …, N) brand preference degree relative index Cj (j = 1, …, M) belongs to the Ls confidence level as evidence of the theory of evidence, language opinion rating L = {Ls, s = 0, 1, …, T} as the overall recognition frame. Set Q (i, j, s) is the jth evidence of brand Ai, define its basic probability assignment function:
| (1) |
Here, to mark the weight of the index Cj with ωj, to mark decision with mj,s (Ai) expressing the basic probability distribution function produced by the degree of brand Ai preference of the decision-makers and assigned to the language opinion rating on the Ls. mj,L (Ai) expresses that the decision-makers can not describe the degree of brand preference Ai, namely has not been assigned to basic probability distribution function of any language opinion rating Ls (s = 0, 1, …, T).
Set:
| • | mJ(j) (Ai) = m1 (Ai) ⊕ m2 (Ai) ⊕ … ⊕ mJ(j) (Ai), |
| • | mJ(1),s (Ai) = m1,s (Ai) (s = 0, 1, …,T), mJ(1),L(Ai) = m1,L (Ai) |
To use the recursive algorithm of literature (Zhijian and Chao, 2006), we get the comprehensive language evaluation level of the degree of Ai brand preference. Specific algorithm:
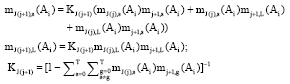 | (2) |
Obviously, ∀s, 0≤s≤T, ms (Ai) = mJ(M),s (Ai), mL (Ai) = mJ(M),L (Ai).
According to the value of mJ(M),s (Ai), mJ(M),L (Ai), Brand Ai (i = 1, …, N) in different language opinion rating confidence level distribution is obtained:
| (3) |
and:
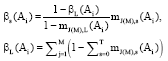 |
To gather the language symbols of different consumers' brand confidence level: From the formula 1-3, it can be known β0(Ai)+β1(Ai)+…+βT(Ai)≤1, In order to facilitate the language of the brand symbols Ai assembly, normalized processing is done to βs(Ai)(s = 0, 1,…, 6), then:
Then confidence level of the brand Ai under various languages opinion rating: ![]() . According to θ function of the two-tuple (Herrera and Martinez, 2000), various standard language opinion rating corresponds to two-tuple: (L0, 0), (L1, 0), …, (LT, 0). Let:
. According to θ function of the two-tuple (Herrera and Martinez, 2000), various standard language opinion rating corresponds to two-tuple: (L0, 0), (L1, 0), …, (LT, 0). Let:
It expresses the result of gathering linguistic symbols of brand Ai (Zhijian and Chao, 2006). According to the Δ-1 function of the two-tuple, there is:
| (4) |
According to the formula (1-4), θ (i) can be transformed into the corresponding the two-tuple:
| (5) |
According to the formula 5, we obtain the corresponding evaluation information of the two-tuple Δ(θ(1)), Δ(θ(2)), …, Δ(θ(N) of brand A = {A1, A2, …, AN}), then according to sequence of the two-tuple nature (Herrera and Martinez, 2000), sorting of the degree of consumers’ brand preference is made.
A CASE STUDY OF THE FAMILY CAR BRAND PREFERENCE SEQUENCE
Suppose some consumer wants to purchase a family car, he is to sort preference of five brands A = {A1, A2, …, A5} to sort the preferences. The family car is expected to hold advanced technology, scientific standards, the reliable quality and the excellent service. This article probes into the factors which affect car brand preference of consumers in the perspective of both behavior and emotion (You et al., 2006) and concludes that these factors composed of five first-level targets: quality and safety of cars, cars visual image, price and maintenance costs, unique spiritual position and post-sale service and twenty-one second-level targets such as power, brake, manoeuvring, security and reliability. The consumer gives the weight of the first-level target and the second-level target according to backgrounds of individual experience, the knowledge and preference which is shown in Table 1.
The consumer gives the linguistic assessment information value of different brands under the second-level target according to backgrounds of individual experience, the knowledge and preference, specific information is shown in the Table 2.
| Table 1: | Indexes and weights affecting the family car brand preference |
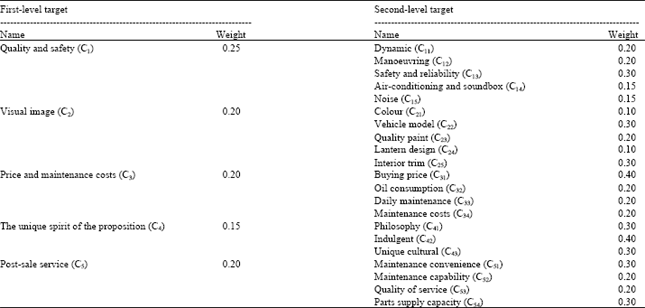 | |
| Table 2: | The consumers language evaluation value |
 | |
According to the formula 1, at first, basic probability distribution function values of the different brands under second-level target is obtained, then using the formula 2 and 3, the basic probability distribution function values of the different brands are gathered to obtain the language opinion rating basic probability distribution function of brand Ai (i = 1, 2, 3, 4, 5) under the first-level target Cj (j = 1, 2, 3, 4, 5).
The formula 2 and 3 are used to together the language opinion rating basic probability distribution function under the first-level target, at the same time, to carry on normalized processing to get the overall distribution of brand language opinion rating.
The formula 4 is employed to deal with the dates of the Table 2, to get the two-tuple function value of Δ-1 of different brands:
θ (1) = 4.5124, θ (2) = 3.7773, θ (3) = 3.7343, θ (4) = 4.1666, θ (5) = 4.4677 |
According to the formula 5, θ(i) can be transformed into the corresponding the two-tuple Δ(θ(i)):
Δ(θ(1)) = (5,-0.4876), Δ(θ(2)) = (4,-0.2227), Δ(θ(3)) = (4,-0.2657), Δ(θ(4)) = (4,0.16666), Δ(θ(5)) = (4,0.4677) |
The ordering of the five family car brand preference is obtained, according to the ordered nature of the two-tuple: A1 ![]() A2
A2 ![]() A3
A3 ![]() A4
A4 ![]() A5, here “
A5, here “ ![]() ” expresses “surpass”.
” expresses “surpass”.
CONCLUSION
In marketing activities, the consumer product attitude, namely the brand preference, has great influence on consumers’ potential future purchase behavior. When the consumer decides to choose the products of different brands, he always chooses that of a high degree of preference. Moreover, the psychological characteristics revealed in purchase decision-making directly affect the enterprise’s choice of the target market, product formulation and promotion strategies, accordingly, the studies on consumer's brand preference behavior have become the centre of marketing research. At present, the consumer's brand preference sequence research in certain environment has been perfect and mature. But in real life, due to the incompletion of brand preference ranking system’s information and the loss of data, measurement of the preference degree by means of traditional mathematical modeling is of low reliability.
In response, the study fully considers many uncertainties of the consumer brand preference system, based on the analysis of existing achievements. It puts forward a consumer brand preference sequence model, comprehensively using evidential reasoning and the relevant operators of two-tuple. Finally, by a case study of the sequence of family car brand preference, the concrete application process is elaborated in detail which renders the theoretical significance as well as practicality and more accords with the actual situation.
ACKNOWLEDGMENT
This study thanks the Natural Science Key Foundation of Anhui Provincial Education Department (No. KJ2010A039) and Natural Science Foundation of Anhui Province (No.11040606M24).
REFERENCES
- Currim, I.S., 1982. Predictive testing of consumer choice models that not subject to independence of irrelevant alternatives. J. Marketing Res., 19: 208-222.
Direct Link - Eliashberg, J. and A.K. Manrai, 1992. Optimal positioning of new product-concepts: Some analytical implications and empirical results. Eur. J. Operat. Res., 63: 376-397.
CrossRef - Herrera, F. and L. Martinez, 2000. A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst., 8: 746-752.
CrossRef - Matsatsinis, N.F. and A.P. Samaras, 2000. Brand choice model selection based on consumers multicriteria preferences and experts knowledge. Comput. Operat. Res., 27: 689-707.
CrossRef - Shiv, B. and A. Fedorikhin, 1999. Heart and mind in conflict: The interplay of affect and cognition in consumer decision making. J. Consum. Res., 26: 278-292.
Direct Link - Tversky, A. and D. Kahneman, 1991. Loss aversion in riskless choice: A reference-dependent model. Q. J. Econ., 9: 1039-1061.
Direct Link - Walsh, G., V.W. Mitchell and T. Hennig-Thurau, 2001. German consumer decision-making styles. J. Consum. Affairs, 35: 73-95.
CrossRef - Wu, G.H. and D.H. Pan, 2004. A fuzzy method of ranking consumer's preference for brand. Syst. Eng. Theory Practice, 9: 28-32.
Direct Link - You, H., T. Ryu, K. Oh, M.H. Yun and K.J. Kim, 2006. Development of customer satisfaction models for automotive interior materials. Int. J. Ind. Ergon., 36: 323-330.
CrossRef