
Ning Chen
College of Computer Science, Xi`an Polytechnic University, 710048, Xi`an, China
Xing Li
College of Computer Science, Xi`an Polytechnic University, 710048, Xi`an, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 7 | Page No.: 812-815







ABSTRACT
Under the limitation of cost and external condition, training example set cannot be large enough to satisfy requirement, moreover, single training example frequently exists. Therefore, this study introduces a multi-resolution pyramid algorithm into image process, which can transform single training example to a series of low-resolution sub-images as training example set to train attention mechanism of Adaptive Resonance Theory (ART), a fact that accord with theory of visual perceive, i.e., adjusting attention focus to implement visual perceive from coarse to fine. Moreover, with cooperation of polynomial spline algorithm, multi-resolution pyramid algorithm will lead to great efficiency and low complexity.
PDF Abstract XML References Citation
Received: October 30, 2011;
Accepted: February 15, 2012;
Published: March 26, 2012
How to cite this article
Ning Chen and Xing Li, 2012. Adaptive-Resonance-Theory Training Algorithm for Image Based on Single Training Example. Information Technology Journal, 11: 812-815.
DOI: 10.3923/itj.2012.812.815
URL: https://scialert.net/abstract/?doi=itj.2012.812.815
DOI: 10.3923/itj.2012.812.815
URL: https://scialert.net/abstract/?doi=itj.2012.812.815
INTRODUCTION
In the field of pattern recognition, many kinds of learning models have developed, which can be used to automatically complete some verification tasks. For example, template matching algorithms, artificial neural network algorithm (He et al., 2011), support vector machines based on statistical learning theory etc. (Niblack et al., 1994). Under normal conditions, these algorithms work very well, but which often require a training set through some training algorithm to determine the model parameters and sometimes requires a large training sample set. In practice, due to cost and time constraints, it is difficult to obtain the required training set. For example, in authentication applications, we only have a single individual face photographs to identify and retrieve samples. Currently, based on statistical learning theory and support vector set theory, some machine learning algorithm for a limited sample set was proposed, but they cannot handle single sample situation. Carpenter and Grossberg proposed a new neural network based on Adaptive Resonance Theory (ART) (Carpenter and Grossberg, 1987), which has unsupervised self-learning ability in non-stationary, noisy environment without teachers, furthermore its learning process is self-organization real-time learning process, which can quickly identify the learned sample and can quickly adapt to the new sample that is not learned. It can extract common characteristics in a series of images through adaptive resonance. In this way, ART can be trained through resolution of a single sample into a series of sub-images, coarse to fine, by polynomial spline pyramid algorithm. Because input images for ART training is a series of images which are decomposed from the same sample, they will absolutely contain common features, thus ensuring the convergence of the algorithm.
This study proposes a training algorithm for ART based on single sample. ART has bionic ability for biological systems, with a valuable tradeoff of the conflict between stability and flexibility and a valuable tradeoff between long-term memory and short-term memory (Francis, 1996). Simultaneously, a standard image is decomposed into a series of multi-precision sub-image using the polynomial spline pyramid algorithm. The polynomial spline pyramid algorithm can improve the efficiency of the algorithm and convergence performance through the strategy from coarse to fine, as is consistent with human visual characteristics. In this way, the algorithm can overcome the contradiction that usual artificial intelligence algorithms need a large training set for training, but a large training set cannot be actually provided.
ART STRUCTURE AND PRINCIPLES
ART network is divided into attention subsystem and orienting subsystem. Attention subsystem consists of high-level network (recognition layer) and the underlying network (comparison layer). After external input pattern into the comparison layers, the adaptive filtering, contrast enhancement and normalization was executed, then external input pattern is into the recognition layer. If a certain pattern class which has been stored in the recognition layer can produce good resonance with the input pattern, then the input pattern fall into the pattern class; otherwise it is considered as a new pattern class and a new pattern class would be established in the recognition layer through orienting subsystem.
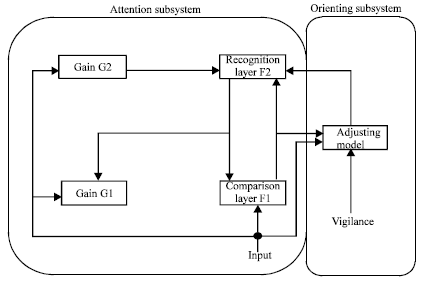 | |
| Fig. 1: | Basic schema of ART |
The basic schema of the ART network, including: comparison layer F1, recognition layer F2, gain control module G1, G2 and adjusting model, as shown in Fig. 1.
SUPERVISED ART ALGORITHM
ART network consists of two layers, comparison layer F1 and recognition layer F2, which are linked using the weighted coupling and vigilance parameters. Vigilance parameter is used to control the extent of aggregation and inter-class distance while classification. First F1 layer accept input pattern, then F2 layer process it, finally it is fed back to the F1 layer, as shown in Fig. 1. Output of a polynomial spline pyramid algorithm can be treated as input of a supervised ART network. Since the input is sub-images of an image with different focus, they should belong to the same pattern class; therefore vigilance parameter should be adjusted to make output of supervised ART network into the same pattern class according to output of supervised ART network. Adjustment process will be finished until end of the network training. Therefore, ART network has become a supervised ART network. First ART network will compare results of F1 layer and F2 layer and then adjust the weight value to make the output pattern into same pattern class, if when the right parameters cannot be found for the weight value, a new pattern class of output will be produced. Therefore, a supervised ART network can be achieved through adding an intermediate layer to modify the structure of ART network. In the learning process of the supervised ART network, if there is misclassification, which cannot be corrected by adjusting the weight value, then the vigilance parameter will be adjusted and the previous parameters will be withdrawn from the intermediate layer. Finally, the ART network will start again from the initial state, start re-training, so as to reach an appropriate value of vigilance parameter.
MULTI-RESOLUTION ANALYSIS AND IMAGE PYRAMID
Multi-resolution analysis (MRA), also known as multi-scale analysis, it is a theory based on the concept of function space (Liejun et al., 2008). If the scale is considered as the camera lens, while the descending scale transformation, it is equivalent to the camera lens from far and near close to the target. If in the large-scale space, the lens is far from the observed target, the target can only be seen the general overview; if in a small-scale space, the lens is near the observed target, the subtle part of the target can be observed (Liao and Cho, 2008). Thus, with the descending scale changes in the scale, the target from coarse to fine can be observed, as is multi-resolution or multi-scale ideas. Because the multi-resolution analysis is multi-level decomposition of the image, it is not only efficient but also providing the image information at different scales, furthermore most of the energy after transformed are concentrated in the low frequency part, thus multi-scale analysis being adopted for most of image processing.
The two images, before shrinking and after shrinking, should be maintained as similar as possible, if the length and width of an image will be shrunk to 50% (shrinking the original image to 1/4). Then iterate this process until the image is shrunk to a point, hence the resulting sequence of images is called image pyramid. This approach is often referred to as multi-resolution representation. Multi-resolution image processing and analysis is very similar to the biological visual system to some extent. For example, the low-resolution image processing and analysis is very similar to the peripheral visual function of biological visual system. In the human retina, rod-shaped nerve cells in surrounding optic region are sensitive to changes in a broad but vague scene. Understanding of rod-shaped nerve cells in surrounding optic region on changes in scene can remind the human brain to control human eye to observe the latest events, if the events have valuable enough to observed scene. Then gaze behavior of human eye should use much higher fovea resolution than rod-shaped nerve cells, to carefully observe interesting objects. This foveal visual function is similar to the high-resolution image processing and understanding.
Polynomial spline pyramid algorithm can decompose an image into a series of sub-images and organize them into a pyramid data structure (Khan et al., 2007). These sub-images can be expressed as a compounding of some continuous piecewise polynomial of order n, which have derivative from first order to n-1. Polynomial spline is higher computational efficiency, lower computational complexity, than the Gaussian, but also has the unlimited approximation accuracy of Gaussian. Polynomial spline pyramid algorithm provides two operators, REDUCE and EXPAND operators. REDUCE operator acting on images can generate the low-resolution sub-image, while the EXPAND operator acting on the image can produce high-resolution sub-images. therefore the REDUCE operator acting on the sample image is adopted to get low-resolution images, then REDUCE operator acting on these low-resolution images get lower resolution images, as has been repeated until the low-resolution image will be degraded to a point. This process simulates the human visual system, that is, moving naked eye from near to far, the image on the retina finally becomes a point. Through this iterative process, finally a series of low-resolution sub-image can be achieved and they all have common characteristics, because they are different precision images of the same scene. REDUCE operator (Unser et al., 1993) is as follows:
| (1) |
SINGLE TRAINING EXAMPLE ALGORITHM
A single training sample algorithm, combined with HOUGH transform algorithm, is as follows. The learning process is a primary step. First, the decomposition of the polynomial spline pyramid algorithm for the standard image into a series of low-resolution sub-images; Second, edge detection processing for each low-resolution sub-images using SOBEL operator; Then application of HOUGH transform to each sub-images having been processed by edge detection to obtain the vector set including the coordinates and the length of the lines in the image; Finally a supervised ART network is given, including two outputs, one is the correct classification, the other is the wrong classification and a input corresponding the vector set of HOUGH transform.
| Algorithm ARTNNTraining |
 |
EXPERIMENTAL ANALYSIS
Vigilance parameter is an important parameter of a supervised ART network for simulation of visual attention mechanisms in the human brain, an indication of the human brain’s sensitivity to external stimuli. Therefore, simulation experiments on vigilance parameter were performed using MATLAB. The number 1234 in Fig. 2a is the training set; Fig. 2b-f are training results of a supervised ART network. In Fig. 2b-e, for the vigilance parameter of 0.7, because the difference between 3 and 2 is so small that the supervised ART network cannot distinguish 3 from 2, 2 and 3 will be classified as the same pattern, thus confusion arising. And if the vigilance parameter is greater than 0.95, a good recognition can be achieved, as shown in Fig. 2f.
 | |
| Fig. 2(a-f): | Training process of a supervised ART network. (a) Training set, (b-e) Training result with vigilance value of 0.7 and (f) Training result with vigilance value of 1.0 |
CONCLUSION
This study begins with discussion on the perceptual organization model based on the attention mechanism, followed by simulation of image processing in the primary stage of visual feature extraction, the intermediate stage of perceptual organization and advanced stage of connectionism network. The main tasks of the three stages are: the primary stage to extract perception features, namely multi-scale edge extraction; intermediate stage to combine local information into independent target (edge) according to visibility, namely perceptual segmentation (edge); advanced stage to select the target (edge) by attention mechanism. Therefore a supervised ART network can simulate attention mechanisms to overcome the limitations of a single sample.
Combination of polynomial spline algorithm, simulation experiments using MATLAB achieved good results with a single training sample algorithm to train a supervised ART network. Although, not perfect, it has the potential to improve the accuracy, because it is consistent with human understanding of object, comparison of object and search of object. Furthermore, the development of bionic artificial intelligence technology is the current direction. Meantime, this algorithm can be improved by the following methods to improve accuracy and performance (Wang et al., 2002), such as modifying comparison algorithm in the supervised ART network (Sui and Ren, 2006), using the Hausdorff distance as a standard of comparison. Furthermore more effective de-noising algorithms can be employed to eliminate noise (Hu and Duan, 2006), to reduce the interference on image processing.
ACKNOWLEDGMENT
This work is supported by Foundation of the Education Department of ShaanXi Province (2010JK562), Guidance Project of China National Textile Industry Council (2010076), Xi’an Polytechnic University Foundation Research Project (XGJ07008) and the Innovation Fund Project for Graduate Student (chx110917).
REFERENCES
- Niblack, C.W., R. Barber, W. Equitz, M.D. Flickner and E.H. Glasman et al., 1994. The QBIC project: Querying image by content using color, texture and shape. Proceedings of the SPIE Storage and Retrieval for Image and Video Databases, February 1, 1993, San Jose, CA., USA., pp: 173-181.
CrossRef - Carpenter, G.A. and S. Grossberg, 1987. ART 2: Self-organization of stable category recognition codes for analog input patterns. Applied Optics, 26: 4919-4930.
Direct Link - Unser, M., A. Aldroubi and M. Eden, 1993. The L2 polynomial spline pyramid. IEEE Trans. Pattern, Anal. Mach. Intell., 15: 364-379.
CrossRefDirect Link - Liejun, W., J. Zhenhong and L. Zhaogan, 2008. Multi-resolution signal decomposition and approximation based on SVMS. Inform. Technol. J., 7: 320-325.
CrossRefDirect Link - Khan, M.A.U., M.K. Khan, M.A. Khan and M.T. Ibrahim, 2007. Endothelial cell image enhancement using non-subsampled image pyramid. Inform. Technol. J., 6: 1057-1062.
CrossRefDirect Link - Liao, H.C. and Y.C. Cho, 2008. A new calibration method and its application for the cooperation of wide-angle and pan-tilt-zoom cameras. Inform. Technol. J., 7: 1096-1105.
CrossRefDirect Link - He, C., F. Lang, H. Li and H. Wang, 2011. Simplified PCNN based MR images grayscale inhomogeneity real-time calibration. Inform. Technol. J., 10: 1437-1441.
Direct Link - Wang, X.X., D.D. Liang, W.P. Hu, Y.W. Qin, Y.P. Han and Z.Y. Li, 2002. The study of the enhancement methods for the medical digital image. J. Guangxi Normal Univ., 20: 23-26.
Direct Link