
Ali Shadrokh
Department of Statistics, University of Payame Noor, 19395-4697 Tehran, Iran
Parviz Nasiri
Department of Statistics, University of Payame Noor, 19395-4697 Tehran, Iran
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 18 | Page No.: 3333-3337







ABSTRACT
In this study, first we derived classical estimators for the shape parameter of the minimax distribution using un-grouped data and also consider relationship between them. We compare the classical estimators based on their mean squared errors (MSE's). Then, we obtain classical estimators of the shape parameter of this distribution under grouped data. In all cases, we considered both point and interval estimations. These the point and interval estimations are compared empirically using monte-carlo simulation.
PDF Abstract XML References Citation
Received: June 11, 2011;
Accepted: September 21, 2011;
Published: October 12, 2011
How to cite this article
Ali Shadrokh and Parviz Nasiri, 2011. Estimations on the Minimax Distribution using Grouped Data. Journal of Applied Sciences, 11: 3333-3337.
DOI: 10.3923/jas.2011.3333.3337
URL: https://scialert.net/abstract/?doi=jas.2011.3333.3337
DOI: 10.3923/jas.2011.3333.3337
URL: https://scialert.net/abstract/?doi=jas.2011.3333.3337
INTRODUCTION
In various fields of science such as biology, engineering and medicine it is not possible to obtain the measurements of a statistical experiment exactly but is possible to classify them into intervals, rectangles or disjoint subsets (Al Odat and Al-Saleh, 2000; Heitjan, 1989; Surles and Padgett, 2001; Wu and Perloff, 2005; Pipper and Ritz, 2007). For example, in life testing experiments, we observe the failure time of a component to the nearest hour, day or month. Data for which true values are known only up to subsets of the sample space are called grouped data. In general grouped data can be formulated as follows: Let X1, X2,..., Xn be a random sample from the density f (x;θ), x ε χ, θ ε Θ and χ1, χ2,..., χk+1 be a partition of the sample space χ and N1 = the number of Xj's that fall in χj for j = 1, 2,..., k+1. The set of pairs {(χ1, N1),..., (χk+1, Nk+1)} is called grouped data. The grouped data problem is to use these data to draw inferences about the parameter θ. Since, we don’t have complete information about the sample, then there will be a loss in the information due to the grouping. Schervish (1995) shows the following:
where, ![]() and
and ![]() are the fisher's information number obtained from
are the fisher's information number obtained from ![]() and
and ![]() , respectively and:
, respectively and:
is the conditional score function. If we replace ![]() by the grouped sample n = (N1, N2,…, Nk+1), then
by the grouped sample n = (N1, N2,…, Nk+1), then ![]() for all θ, which means that the information in the sample
for all θ, which means that the information in the sample ![]() about θ is reduced to
about θ is reduced to ![]() because of grouping. Kuldorff (1961) considered non-bayesian estimation from grouped data when the data come from normal and exponential distributions. Al Odat and Al-Saleh (2000) considered the Bayesian estimation from grouped data when the underlying distribution is exponential. Alodat et al. (2007) obtained Bayesian prediction intervals from grouped data when the underlying distribution is exponential. Aludaat et al. (2008) obtained the bayesian and non-bayesian estimation from grouped data when the underlying distribution is Burr type X. Also, Shadrokh and Pazira (2010) obtained the classical and Bayesian estimation from grouped and un-grouped data when the underlying distribution is Exponentiated Gamma.
because of grouping. Kuldorff (1961) considered non-bayesian estimation from grouped data when the data come from normal and exponential distributions. Al Odat and Al-Saleh (2000) considered the Bayesian estimation from grouped data when the underlying distribution is exponential. Alodat et al. (2007) obtained Bayesian prediction intervals from grouped data when the underlying distribution is exponential. Aludaat et al. (2008) obtained the bayesian and non-bayesian estimation from grouped data when the underlying distribution is Burr type X. Also, Shadrokh and Pazira (2010) obtained the classical and Bayesian estimation from grouped and un-grouped data when the underlying distribution is Exponentiated Gamma.
Despite the many alternatives and generalizations (Kotz and van Dorp, 2004; Nadarajah and Gupta, 2004), it remains fair to say that the beta distribution provides the premier family of continuous distributions on bounded support (which is taken to be (0, 1)). The beta distribution, Beta (a, b), has density:
where, its two shape parameters a and b are positive and B (.,.) is the beta function. Beta densities are unimodal, uniantimodal, increasing, decreasing or constant depending on the values of a and b relative to 1 and have a host of other attractive properties. Jones (2007) looks at an alternative two-parameter distribution on (0, 1) which he has called the minimax distribution, Minimax x (λ, θ), where its two shape parameters λ and θ are positive. It has many of the same properties as the beta distribution but has some advantages in terms of tractability. Its density is:
| (1) |
And its the distribution function is:
| (2) |
This is not entirely new and alert readers might recognize it in some way but it seems that this distribution has not been investigated systematically before nor has its relative interchangeability with the beta distribution been appreciated. For example, minimax densities are also unimodal, uniantimodal, increasing, decreasing or constant depending in the same way on the values of α and θ. In this study, without loss of generality we take λ = 1 and we consider the un-grouped and grouped data problems when the density f (x; θ) is Minimax (θ), the Eq. 1.
CLASSICAL ESTIMATIONS BASED ON THE UN-GROUPED DATA
Here, we obtain the classical estimators of θ and compare these estimators based on their mean squared errors (MSE's). Also, we present the confidence intervals for θ.
Classical point and interval estimations: Let X1, X2,..., Xn be a random sample from density (1). The likelihood function is given by:
| (3) |
Then the log-likelihood function is:
| (4) |
Hence:
Thus the MLE of θ is:
| (5) |
where,
For the more details see Shadrokh and Pazira (2010).
Here, we obtain the Uniformly Minimum Variance Unbiased Estimator (UMVUE) of θ. Since family of density (1) belongs to an exponential family, therefore, statistic T is a complete sufficient statistic for θ. It is easy to show that statistic T is distributed as gamma distribution with parameters n and 1/θ, with the density g (t) = θ'' (Γ (n))-1 tn-1 e-θt; t>0, θ>0. Thus:
Hence, the UMVUE of θ is:
| (6) |
We can find the minimum mean squared error (MinMSE) estimator in the class of estimators of the form u/T. Therefore:
Whereas:
thus:
and:
then:
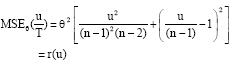 | (7) |
The derivative of r (u) is:
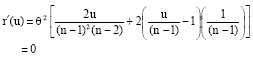 |
that thereby u = n-2. Thus, the Min MSE estimator of θ is:
| (8) |
From Eq. 7, the MSE of the classical estimators of θ are calculated as follow:
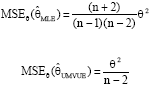 |
and:
For the more details see Shadrokh and Pazira (2010). It is easy to show that:
Now, we find a 100 (1-τ)% confidence interval for θ with obtain L and U, where, P (L<θ<U) = 1-τ.
Let X1, X2,..., Xn be a random sample from Minima x (θ). Since
thereby 2θT∼χ2 (2n), thus:
or:
Therefore a classical 100 (1-τ)% confidence interval for θ is given by:
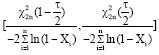 |
CLASSICAL ESTIMATIONS BASED ON THE GROUPED DATA
Here, we obtain the MLE estimators of θ and also the fisher's information number when the data given in groups. Also, we use the fisher's information number to construct a asymptotic confidence interval for θ.
Likelihood function and MLE: In this subsection, first we derive the likelihood density based on the grouped data. Let X1, X2,..., Xn be a random sample from Minia x(θ). Assume that the sample space of f (x; θ) is partitioned into k+1 equally-spaced intervals as follows. Let Ij = [(j-1) δ, jδ], j = 1,..., k and Ik+1 = (kδ, ∞), δ>0. If Nj denotes the number of Xj's that fall in Ij, j = 1, 2,..., k+1, then n = N1+...+Nk+1. Let :
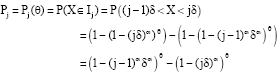 |
for j = 1,..., k and Pk+1 = Pk+1 (θ) = P (X>kδ) = (1-ka δa)θ.
If we let Aj = log (1-(j-1)a δa), then ![]() , for j = 1,..., k and
, for j = 1,..., k and ![]() . So the density of n = (N1, N2,..., Nk+1) is given by the multinomial distribution as follows:
. So the density of n = (N1, N2,..., Nk+1) is given by the multinomial distribution as follows:
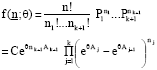 | (9) |
where, C is a normalizing constant.
In continue, we find the MLE of θ based on the density Eq. 9. To do this, we maximize the log-likelihood function:
The first derivative of the log-likelihood is:
| (10) |
The M.L.E for θ is the solution of ∂ log f (n; θ)/∂θ = 0. So the M.L.E is ![]() such that:
such that:
| (11) |
We use the notation ![]() to denote the M.L.E of θ obtained from the grouped data. We can solve Eq. 11 by Newton-Raphson method. Hence, solution of the equation is:
to denote the M.L.E of θ obtained from the grouped data. We can solve Eq. 11 by Newton-Raphson method. Hence, solution of the equation is:
| (12) |
Where:
And:
Here, the initial solution θ0 should be selected from the M.L.E of θ based on the un-grouped data, Eq. 5.
Fisher's information number and confidence interval: To find the fisher's information number contained in the grouped sample about θ, we find the expectation of the second derivative of the log-likelihood. So:
| (13) |
Where:
If IG (θ) denotes the Fisher's information number from grouped data, then:
and since E[Nj] = nPj, thus:
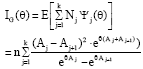 | (14) |
Using IG (θ), we can find a large sample (1-α)100% confidence interval for θ as follows:
| (15) |
Simple calculations can show that the fisher's information number about θ in a random sample X1, X2,..., Xn from Eq. 1 is I (θ) = n/θ2.
Now, we compare all these estimators in terms of biases and mean squared errors (MSE's), using monte-carlo simulation.
| Table 1: | Biases and Mean Squared Errors (MSE's) of the point estimates and lengths of the interval estimates from the un-grouped and grouped data, when k = 4, δ = 1, θ = 5 and τ = 0.05 (Upper value in each cell refers to MSE and lower value to Bias) |
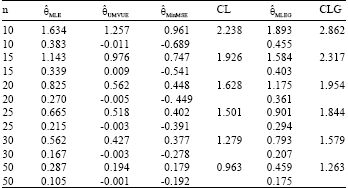 | |
| CL: 95% confidence length. CLG: 95% confidence length under grouped data | |
SIMULATION STUDY
The estimators ![]() and
and ![]() are the classical estimations of the shape parameter of the Minimax distribution obtained from the un-grouped data. Meanwhile,
are the classical estimations of the shape parameter of the Minimax distribution obtained from the un-grouped data. Meanwhile, ![]() is the MLE estimator of θ based on the grouped data. We also use the notations CL to denote the 95% confidence length for θ based on the un-grouped data and use notation CLG to denote the 95% confidence length for θ based on the Grouped data.
is the MLE estimator of θ based on the grouped data. We also use the notations CL to denote the 95% confidence length for θ based on the un-grouped data and use notation CLG to denote the 95% confidence length for θ based on the Grouped data.
Our main aim is to compare these estimators in terms of Biases and MSE's. As mentioned earlier, ![]() and hence its MSE can not be put in a convenient closed form. Therefore, MSE's of the estimators are empirically evaluated based on a monte-carlo simulation study of 1000 samples. We generated these samples from Minimax distribution with θ = 5 by using newton-raphson method by MATLAB. The simulation study was carried out with sample size n = 10, 15, 20, 25, 30 and 50. We put these samples into five intervals (k = 4) with δ = 1. All the results are summarized in Table 1.
and hence its MSE can not be put in a convenient closed form. Therefore, MSE's of the estimators are empirically evaluated based on a monte-carlo simulation study of 1000 samples. We generated these samples from Minimax distribution with θ = 5 by using newton-raphson method by MATLAB. The simulation study was carried out with sample size n = 10, 15, 20, 25, 30 and 50. We put these samples into five intervals (k = 4) with δ = 1. All the results are summarized in Table 1.
CONCLUSION
In this study, we obtained classical estimators for the shape parameter of the Minimax distribution based on the grouped and un-grouped data. We considered both point and interval estimators. Our observations about the results are stated in the following points:
| • | Table 1 shows that the classical estimates based on the un-grouped data have the smallest estimated MSE's as compared with the classical estimates based on the grouped data. It is immediate to note that MSE's decrease as sample size increases. On the other hand the MLE's are overestimation, this is true for both un-grouped and grouped data but UMVUE's and the Min MSE estimates are underestimation. Meantime, the confidence intervals work quite well unless the sample size is very small and this is true for both un-grouped and grouped data |
| • | Whereas, MLE estimator work quite well, therefore we suggest to use MLE method for estimating the shape parameter of Minimax distribution and this is true for both un-grouped and grouped data. In general, the estimator yield of the grouped data work very well. Therefore, we can use the estimator presented when the data given in groups, for example in life testing experiments |
REFERENCES
- Al Odat, M.T. and M.F. Al-Saleh, 2000. Bayesian estimation using grouped data with application to the exponential distribution. Soochow J. Math., 25: 343-357.
Direct Link - Aludaat, K.M., M.T. Alodat and T.T. Alodat, 2008. Parameter estimation of Burr type X distribution for grouped data. J. Appl. Math. Sci., 2: 415-423.
Direct Link - Jones, M.C., 2007. The Minimax Distribution: A Beta-Type Distribution With Some Tractability Advantages. The Open University, UK., pp: 1-21.
Direct Link - Pipper, C.B. and C. Ritz, 2007. Cheking the grouped data version of the cox model for interval-grouped survival data. Scand. J. Stat., 34: 405-418.
CrossRefDirect Link - Surles, J.G. and W.J. Padgett, 2001. Inference for reliability and stress-strength for a scaled Burr type X distribution. Lifetime Data Anal., 7: 187-202.
CrossRef - Wu, X. and J.M. Perloff, 2005. Chinas income distribution: 1985-2001. Rev. Econ. Stat., 87: 763-775.
CrossRef