
Qiang Pu
School of Computer Science and Engineering, University of Electronic Science and Technology of China, 610054, Chengdu, Sichuan, People’s Republic of China
Daqing He
School of Information Sciences, University of Pittsburgh, Pittsburgh, PA 15260, USA
Information Technology Journal
Year: 2010 | Volume: 9 | Issue: 2 | Page No.: 236-246







ABSTRACT
How to effectively generate clusters and use the information in clusters to improve information retrieval performance are still open research questions. By viewing a document as an interaction of a set of independent hidden topics, we propose a novel semantic clustering technique using independent component analysis. Then within language modeling framework, we apply the obtained semantic topic clusters into the estimation process of relevance model. We expect that semantic clustering will filter out those noisy documents so that the estimation of relevance model is only based on relevant documents and some useful semantic information. A semantic cluster is activated to be the most similar to a user’s information need by user’s query, the documents in the activated semantic cluster and the keywords of representing the activated semantic cluster are used for the estimation of relevance model. Therefore, we obtain a semantic cluster based relevance language model that uses pseudo relevance feedback technique without requiring any relevance training information. We applied the model in experiments on five TREC data sets. The experiment results show that our model can significantly improve retrieval performance over previous language models including relevance-based language models. We think that the main contribution of the improved performance comes from the estimation of relevance model on the semantic cluster that is closely related to a user’s information need.
PDF Abstract XML References Citation
How to cite this article
Qiang Pu and Daqing He, 2010. Semantic Clustering Based Relevance Language Model. Information Technology Journal, 9: 236-246.
DOI: 10.3923/itj.2010.236.246
URL: https://scialert.net/abstract/?doi=itj.2010.236.246
DOI: 10.3923/itj.2010.236.246
URL: https://scialert.net/abstract/?doi=itj.2010.236.246
INTRODUCTION
Pseudo Relevance Feedback (PRF), which assumes that top-ranked retrieved documents are relevant to the user’s information need, is an effective method of enhancing user’s initial query to improve the retrieval performance.
However, not all top-ranked retrieved documents are truly relevant and the noise introduced by non-relevant documents could cause the expansion of the query drifting away from the original query topic and may hurt performance for about one-third of a given set of topics (Sakai et al., 2005). If the relevant documents in the top-ranked retrieved set can be carefully identified, the query expansion (Efthimiadis, 2000) or query model update (Zhai and Lafferty, 2001) based on the relevant documents will be closer to user’s information need.
Clustered-based retrieval method may group content similar documents into a cluster in which the documents match to the users’ need if that cluster is relevant.
Within the language modeling framework (Ponte and Croft, 1998). Liu and Croft (2004) demonstrated that cluster-based retrieval can generate significantly better effectiveness over non-cluster retrieval if good clusters can be identified and used. They used K-means algorithm for clustering documents and selected certain clusters for smoothing the document language model.
Lee et al. (2008) improved PRF by using document clusters to find dominant documents and iteratively feeding the documents to emphasize the core topics of a query. They found that this resampling approach contributed to higher relevance density for feedback documents and resulted in more accurate retrieval.
Wang et al. (2008) studied negative examples in relevance feedback. Although, clustering was not explicitly employed, their way of handling negative examples could be easily extended into explicitly clustering according to the dissimilarity of returned documents to the query.
Sakai et al. (2005) proposed a selective sampling method for PRF, where the number of selected documents and that of the expansion terms for each topic were adjustable. They used memory resetting algorithm to select documents.
Wei and Croft (2006) proposed to use LDA-based language model for clustering and also allowed a document to be in multiple topics. They reported that LDA-based retrieval is a promising method for IR.
This study proposes a semantic clustering approach to organizing the top-ranked documents with similar semantic topics into a cluster, then uses documents in a semantic cluster close to the user’s query, not the whole top-ranked documents, as feedback documents for a better PRF within the language modeling framework.
Our clustering approach is based on a high order statistical method called Independent Component Analysis (ICA) (Hyvärinen, 1999), which groups documents in an ICA latent semantic space instead of the traditional semantic space (Deerwester et al., 1990; Hofmann, 1999) which defines latent semantic topics as the dimensions that capture the maximal variance, but maximal variance is not typically considered as a real topic of the data (Hyvärinen, 1999).
The ICA is a method of representing a set of multivariate observations as a linear combination of unknown latent variables that are statistically independent (Hyvärinen, 1999). If we view documents as the interactions of a set of independent latent topics, ICA can reveal the semantic structure in original text data and the latent variables can be thought as the topics in the text data. As a result, documents can be grouped according to their probabilities of belonging to a topic in the latent semantic space constructed by ICA, so we call this clustering method semantic based clustering method. When applied for PRF, we hypothesize that this clustering method will bring some helpful semantic information in generating better clusters on the top-ranked retrieved documents so that relevant and non-relevant documents can be easily separated.
We propose an activation process to select one of semantic clusters identified by ICA, which is most similar to user’s query. This activation performs two roles: first, it activates the documents under the topic, which filters out more noise than that of using all top-tanked retrieved documents as relevance feedback documents. Second, it also activates highly relevant keywords in the topic, on which we can estimate a semantic keywords cluster model that can enhance topic content part of the estimation of a document model.
The key difference of our semantic clustering approach from previous works above is that we cluster documents in a latent semantic space so that the selected clusters are semantically related to the user’s query. The semantic information of clusters can be integrated into the estimation of a language model. For example, the probability of a document belonging to a semantic cluster can be used as a prior, which can differentiate the contribution of each feedback document to the estimation of a document model, but the traditional estimation usually uses a uniform distribution on feedback documents. Another example is that terms from semantic keywords cluster can represent and enhance topic content part when estimating a document model.
We assume that a relevance model (Lavrenko and Croft, 2001) exists between a user’s query and the documents in semantic clusters, so both relevant documents and query can be considered as samples from the relevance model. Relevance model comes from the difficulty in estimating model parameters in the classical probabilistic model when we do not have relevance judgments (Zhai, 2008). We will estimate the relevance model based only on a user’s query, the documents in semantic clusters without any relevance judgments.
SEMANTIC CLUSTERING-BASED RELEVANCE MODEL
Here, we describes clustering method using ICA framework and our semantic clustering-based relevance model.
Maximum likelihood approach for ICA: The ICA model in text data analysis can be described as follows:
| (1) |
where, X is a term-document matrix that holds m observed terms in each row with n documents in each column. A is an unknown mxk mixing matrix with non-orthogonal transformation basis and S is another unknown matrix that holds k latent topics in each row and n document samples in each column. In this paper, we use Bayes Information Criterion (BIC) (Hansen et al., 2001) to determine the k value which indicates how many latent topics exist in a set of documents. Each latent topic si (i = 1, 2,…, k) is mutually independent and non-Gaussian. Therefore:
| (2) |
The term-document matrix X in ICA should be viewed as linear mixtures of latent topics. If the number of topics is assumed to be equal to the number of observed signals, the mixing matrix is square, the goal of ICA is then to find the unmixing matrix W = A-1 based on the observed matrix X. Therefore, we can rewrite Eq. 1 as:
| (3) |
In probabilistic framework, according to Eq. 2 and 3 the probability density function of X is then:
| (4) |
where, |C* represents an absolute value. Because ![]() is also a function of W, we can denote it as
is also a function of W, we can denote it as ![]() . According to Eq. 4, then the likelihood of X is:
. According to Eq. 4, then the likelihood of X is:
| (5) |
Based on the principle of maximum likelihood, if we can estimate a Ŵ such that it makes the maximum of the mathematical expectation of E [l(X,W)], denote it as ![]() , then Ŵ is the solution to the unmixing matrix. If finite samples of n documents are available,
, then Ŵ is the solution to the unmixing matrix. If finite samples of n documents are available, ![]() can be estimated by these finite samples as:
can be estimated by these finite samples as:
| (6) |
We can calculate the gradient of equation for updating the unmixing matrix W in an iterative optimization method.
| (7) |
where, ![]() is the gradient of l(X,W) on W. We denote:
is the gradient of l(X,W) on W. We denote:
where, Φ = -tanh, because it is suitable for the infomax solution to separate super-Gaussian signals, e.g. the text data (Kolenda, 2002). This also implies the source distribution p(S) = 1/π exp (-ln cosh S).
A natural gradient algorithm is used to iteratively estimate the optimal Ŵ:
| (8) |
where, ΔW is a micro-variant matrix neighbor to W, ![]() is the inner product. According to Amari (1998):
is the inner product. According to Amari (1998):
| (9) |
where, α is a learning ratio. When the iterative process stops, we get the solution to W, then the latent topics in a set of documents will be obtained by S = WX.
Preprocessing for ICA: To obtain fast-converging ICA decomposition, to make the mixing matrix square and to cure the ill-posed problem (Lautrup et al., 1995), we can use Principal Component Analysis (PCA) as a preprocessing step to form the latent semantic space before ICA decomposition. The corresponding technique for finding this semantic space is Singular Value Decomposition (SVD) by which the term-document matrix X is decomposed as:
| (10) |
where, L is a diagonal matrix containing k (k<=r) largest singular values of X, r is the rank of X. T and D are the term and document matrix in semantic space, of which columns correspond to the k largest singular values in L. The term matrix T is used as an input for ICA decomposition.
| (11) |
where, A is the ICA mixing matrix and S holds the k latent topics in a set of n documents.
Semantic clustering: According to the solution to unmixing matrix W and Eq. 10 and 11, the independent components can be calculated as follows:
| (12) |
By using softmax normalization (Kolenda, 2002), the value in matrix S can be converted into a probability that describes the degree that a document belongs to a latent topic. For example, see the following matrix in Fig. 1, pij represents document docj belongs to topic topici with a probability pij.
With the help of such a probability, a document docj could be assigned to a latent topic topici according to the highest probability pij, as shown formally as follows:
| (13) |
Therefore, according to Eq. 13, the clustering of documents can therefore converted to a cluster label assignment to each document based on the obtained maximum probability in semantic cluster matrix shown in Fig. 1.
 | |
| Fig. 1: | Semantic cluster matrix |
We can use a set of keywords as representation of a semantic cluster. The probability of a keyword termi belonging to a cluster topicj can be obtained by the back projection technique (Kolenda, 2002) shown as follows:
| (14) |
where, i = (1,…,m), j = (1,…, k). The transformation TA holds the mixing proportions coming from the term space to the lower dimensional semantic topic space (Kolenda, 2002). If the probability p(termi|topicj) is greater than a threshold, we view the termi as the keyword of this semantic topic topicj.
As a result, ICA first helps to cluster documents in the latent semantic space based on its topic separation ability. It then helps to identify a set of representative terms for each latent topic. We expect that the two helps from ICA will enable a semantic model that facilitates a better estimation of a relevance model as in relevance based language models.
Relevance model: Given a set of documents D = (d1,…,dn) and a query Q = (q1,…,qk), to what degree document D is relevant to query Q can be represented by the conditional probability p (R = 1|Q, D). Here, R∈ {0, 1} is a binary relevance random variable. 0 represents that the document and the query are not relevant, whereas 1 represents that the document is relevant to the query. According to Bayes’ rule, p (R = 1|Q, D)∝p (Q, D|R = 1) where, ∝ represents is proportional to. We can further rewrite it by query likelihood as p (Q, D|R = 1)∝ p (D|Q, R = 1). This is the relevance model demonstrated by Lavrenko and Croft (2001).
Relevance model proves to work well even when there is no relevance training data available. If the top-ranked retrieved documents are used to approximate relevant documents, the estimate of relevance model is the estimate the probability of
where, each probability ![]() captures term occurrences in relevant documents (Lavrenko and Croft, 2001; Zhai, 2008). Consider a term w could be generated in a relevant document di, the estimation of the relevance model is then converted to the calculation of probability: p(w|Q, R).
captures term occurrences in relevant documents (Lavrenko and Croft, 2001; Zhai, 2008). Consider a term w could be generated in a relevant document di, the estimation of the relevance model is then converted to the calculation of probability: p(w|Q, R).
Estimation of a semantic clustering-based relevance model: Our approach is inspired by relevance based language models, but we employs a different approach to estimating the conditional probability p(w|Q, R) within the language model framework. We think that it is sub-optimal in the estimation of the relevance model to assume that all top-ranked retrieved documents are relevant documents because not all of them are really relevant. The following gives our estimation of the relevance model.
As stated, we view a document as being generated based on an interaction of a set of independent hidden topics and a set of documents can be grouped into a semantic cluster because they are all related to a hidden topic. If a hidden topic is identified to be relevant to a user’s query, all documents in the semantic cluster associated with the hidden topic could be activated as the relevance documents to the query. Therefore, it is reasonable and optimal to model the relevance based on the semantic clusters.
Based on topical relevance criterion, we select the semantic cluster whose associated hidden topic is the most similar to the user’s query. Therefore, for a query model θQ which is estimated from a user’s query and a semantic model θs which can be estimated from a semantic cluster, we can utilize Kullback-Leibler (KL) divergence to measure the closeness between the two models (Lafferty and Zhai, 2001). The semantic cluster that has the smallest KL divergence value to the query would be activated for estimating the relevance model. This calculation can be written as follows:
| (15) |
where, Θs represents all the semantic clusters derived from ICA algorithm. Term w is from the vocabulary V. Equation 15 clearly indicates that, instead of using all top-ranked retrieved documents, our approach only uses the documents that are semantically most similar to the query for estimating the relevance model.
We use semantic model θs as a bridge to compute the association between each term and the query. Similar to the Model 2 in (Lavrenko and Croft, 2001), we assume that the query terms q1,…, qk are independent to each other, whereas we keep their dependence to term w. That is, it gives the probability of co-occurrence between w and the query in the semantic cluster. We can formally derive the probability p (w|Q, R) formula as follows:
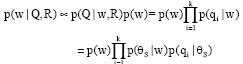 | (16) |
where, qi is the query term in a query Q. Using Bayes’ theorem, p (θs|w) can be transformed to:
| (17) |
A document model θd can be estimated from a document d in the activated semantic cluster model θs, denote as ![]() , then p (w|θs) can be computed as follows:
, then p (w|θs) can be computed as follows:
| (18) |
Note that in Eq. 18, we use the activated semantic model as well as document models to estimate the relevance model. Probability p (d|θs) uses the semantic models to establish different prior probabilities for each document model θd, which implies that document model contains query-related semantic information. This is consistent to our intuition that query-related documents contribute more to the estimation of relevance model than those documents that are dissimilar to the query.
We use both the semantic keywords cluster model θsw and the background model θc to smooth the estimation of a document model θd, the probability of p (w|θd) is computed as follows:
| (19) |
where, c (w,d) is the frequency of a term w in a document d. The semantic keywords cluster model θsw is directly obtained from the semantic keywords cluster generated by ICA using back projection technique (Eq. 14). θc is the collection language model. The parameters of linear interpolation λ1, λ2 and λ3 (λ1+λ2+λ3 = 1) are the coefficients of document topic model, the semantic keywords cluster model and the collection model respectively, which denote the corresponding contribution to the estimation of the document model. The term prior probability p (w) is defined as follows:
| (20) |
where, p (θs) is the prior probability of the semantic models, which can be represented either by the entropy of each semantic cluster or by assuming a uniform distribution over all semantic clusters. In this study, we adopt the uniform distribution approach over the universe of semantic cluster models Θs.
EXPERIMENT SETUP
To examine the performance of our model, we conducted experiments on five data sets taken from previous TREC campaigns: the Associated Press Newswire (AP) 1988-90 with query topics 51-200, Wall Street Journal (WSJ) 1987-92 with query topics 51-200, Financial Times (FT) 1991-94 with query topics 301-400, San Jose Mercury News (SJMN) 1991 with query topics 51-150, Los Angeles Times (LA) with query topics 301-400. For all collections, title field of TREC topics was used as the query. Queries that have no relevant documents in the judged pool for a specific collection had been removed from the query set for that collection. A summary of the collections and query sets is shown in Table 1.
The Indri 2.9 system was used for indexing and retrieval. All collections and queries were stemmed using the Porter stemmer and stop-words were removed as well.
We used queries 51-150 and the AP collection for parameters training and queries 151-200 on AP collection and all other queries and WSJ, SJMN, FT and LA collections for testing. The initial query results were generated using basic query likelihood language model. The implementation of ICA algorithm was from DTU: Toolbox (Kolenda et al., 2002). To design our study in the form of comparative experiments, the basic query likelihood language model and Indri’s implementation of Lavrenko’s relevance based language model were used as the two baselines. We also compared our results to other cluster-based retrieval models. The evaluation measure used Mean Average Precision (MAP).
As stated, our model for PRF involves semantic clustering and the estimation of relevance model. After obtaining initial retrieval results, 50 top-ranked documents were selected for semantic clustering by ICA. During the semantic clustering, the optimal number k of the topic was estimated by Bayes information criterion. When choosing terms to be the cluster representative, we examined the probability of p(termi|topicj), if the probability was greater than an ad hoc threshold 0.3, the term was selected as the representative of the cluster, refer to Eq. 14 for calculation detail.
| Table 1: | TREC collections used for experiments |
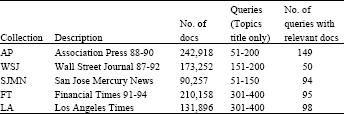 | |
We chose those semantic clusters whose KL divergence was closest to the query during the estimation of the relevance model, see Eq. 15. Based on the selected cluster, we selected n terms w1, …,wn to do the query expansion. The expansion terms were combined with the original query using linear interpolation with a parameter β to tune the relative importance between the expansion terms and the original query. The expanded query in the indri query form is:
Equation 19 contains three parameters λ1, λ2 and λ3 for tuning the estimation of a document model. Intuitively, we assume that λ1>λ2>λ3. The parameters tuning conducted on the training topics demonstrated that the retrieval performance was the best when λ1 was set between 0.4 and 0.7. Therefore, we set these three parameters as: λ1 = 0.45, λ2 = 035, λ3 = 0.2.
EXPERIMENT RESULTS
Semantic clustering-based relevance model in improving retrieval: To control PRF, there are three parameters to be tuned: the number of feedback documents d, the number of feedback terms n and the coefficient β for integrating original query terms with the expanded terms. We performed an exhaustive search to look for the optimal parameter values. The set of parameter values tested in our training were: d∈ {5, 10, 25, 50}, n∈ {10, 25, 50, 75, 100}. For decreasing computation, we fixed β = 0.5 which can result in better and safe results according to Zhai and Lafferty (2001).
Under the X-axes in Fig. 2, there were two lines of numbers. The numbers at the bottom line, that were the numbers of feedback documents d, d = (5, 10, 25, 50), organized the X-axes into four groups. Each group means that the corresponding number of documents were used as feedback documents. The numbers at the top line represented that the numbers of feedback terms n, n = (5, 10, 25, 50, 75, 100) were used as feedback terms in each of the four groups. The Y-axes showed the MAP values corresponding to d and n.
During the training, our semantic clustering based relevance model (SRM in Fig. 2) achieved better performance over Lavrenko and Croft’s relevance model (RM in Fig. 2) in almost all cases. But we did not perform statistical testing on these results, all statistical testing were done on the testing results.
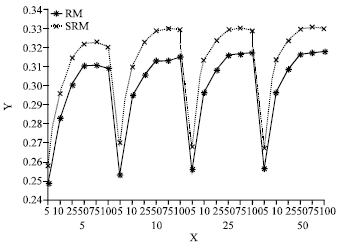 | |
| Fig. 2: | Training of relevance feedback parameters for RM and SRM: the number of feedback documents d and the number of feedback terms n with fixed interpolation coefficient parameter β = 0.5 |
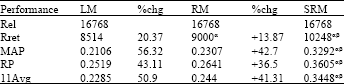
| Table 2: | Performance comparisons on training data sets among three retrieval algorithms |
 | |
| Training: TREC AP collection, queries 51-150 | |
Based on the tuning results and a fixed β value, we selected the following combination of parameters: (1) with SRM, the number of feedback documents d = 50 and the number of feedback terms n = 75; (2) with RM, d = 25, n = 100. Note that, because we only chose the top 50 initial retrieved documents to perform the semantic clustering, which means that the number of documents in a cluster will at most be equal to 50, thus the training parameter d = 50 means that we used all the documents in the selected semantic cluster for relevance feedback.
Table 2 gave the retrieval performance of SRM against that of RM and basic query likelihood language model (LM) on training topics. The superscript α indicated statistically significant improvements over LM and β indicated statistically significant improvements over RM respectively with a 95% confidence by the Wilcoxon test.
In Table 2, comparing SRM against LM and RM, MAPs were improved by 56.32% (0.3292 vs. 0.2106) and 12.2% (0.3292 vs. 0.2307), R-precisions were improved by 43.11% (0.3605 vs. 0.2519) and 36.5% (0. 3605 vs. 0.2641), 11-point averages were improved by 50.9% (0.3448 vs. 0.2285) and 41.31% (0.3448 vs. 0.2440). Meanwhile, the number of relevant retrieved documents of SRM showed 20.37 and 13.87% improvements over LM and RM, respectively. SRM had statistically significant improvements over LM and RM on the all measures. However, there was no significant difference between LM and RM on all measures except the number of relevant retrieved documents.
| Table 3: | Performance comparisons on testing data sets among three retrieval algorithms |
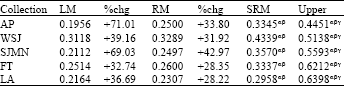 | |
The superscript α indicates statistically significant improvements over LM, β indicates statistically significant improvements over RM, and γ indicates statistically significant improvements over SRM respectively with a 95% confidence by the Wilcoxon test | |
| Table 4: | Performance comparisons on testing data sets among four retrieval algorithms |
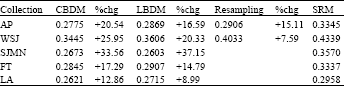 | |
Table 3 showed the performance comparisons on the testing data sets among LM, RM and SRM retrieval algorithms. The parameter setting for obtaining these results were: (1) with SRM, the number of feedback documents d = 50, the number of feedback terms n = 75 and coefficient β = 0.5, (2) with RM, d = 25, n = 100 and β = 0.5. The upper in the last column referred to the upper bound performance when using SRM. We selected the top 50 true relevant documents as feedback documents to obtain the upper bound. This upper bound will help us to establish the best performance that our semantic clustering-based relevance model could produce when all feedback documents are truly relevant. Looking at other columns, our SRM method had significant improvements over LM and RM on all collections whereas RM had no significant difference over LM on all collections.
In Table 4, we compared the retrieval results on the testing data sets with another three important related works: cluster-based method (CBDM) from Liu and Croft (2004), LDA-based method (LBDM) from Wei and Croft (2006) and Resampling method from Lee et al. (2008). We neither implemented CBDM, LBDM and Resampling methods nor conduct statistical tests between our results and that of the three methods in our experiments. The data presented in Table 4 were directly copied from their original publications. From the relative improvement percentages, however, we believe that our method has clear advantage in choosing better relevance documents over the three methods.
Figure 3 showed the comparison of retrieval performance in precision-recall curves. In both training and testing phases, SRM always showed a clearly higher performance than LM and RM. Only at high recall side on WSJ and FT collections, SRM showed a little bit worse performance than that of LM and RM. We also observed that RM and SRM contributed differently to different collections. When trained on the AP collection and tested on WSJ and FT collections, RM had a little bit improvements over LM. However, under the same condition, our SRM method contributed more improvements over LM, especially at low recall side. When tested on the AP collection and the SJMN collection, both RM and SRM had consistent improvement over LM. The LA collection was probably a specific collection for testing relevance based methods. RM could hardly improve the performance over LM and achieved even worse results than LM at the low recall side. Our SRM method also struggled on the LA collection. Its performance had the largest distance to the upper bound and its improvements over RM and LM on the LA collection were also not as salient as that of on other collections.
Semantic clusters in capturing topics: Present evaluation methods not only included extrinsic retrieval performance measures, but also considered the quality of the semantic clusters. By assuming that a set of relevant expansion terms would be topically closer to the true topic than non-relevant expansion terms, we can evaluate the quality of the semantic clusters. We defined four kinds of topics, two topics were estimated from the expansion terms, which were generated from either RM or SRM, written as TopicRM and TopicSRM, a random topic was estimated from the background collection model, written as Collall and a true topic was estimated from the relevant documents of a query, written as Collrel. The topic distance between Topic and Coll was measured by KL divergence:
| (21) |
where, V is the vocabulary, Topic is either TopicSRM or TopicRM, Coll is either Collall or Collrel, Coll∈ {AP, WSJ, SJMN, FT, LA}. We expect that a topic from better expansion terms would have smaller distance to Collrel but larger distance to Collall.
Table 5 gave the results of the comparison of topic distance between TopicSRM (represented as SRM in Table 5), TopicRM (RM in Table 5) to Collall (All in Table 5) and Collrel (Rel in Table 5) on testing collections. Symbol L and S meant that TopicSRM had larger or smaller topic distance than that of TopicRM to Collall and Collrel, respectively. B, W and E meant that TopicSRM has better, worse or equal MAP value than TopicRM, respectively.
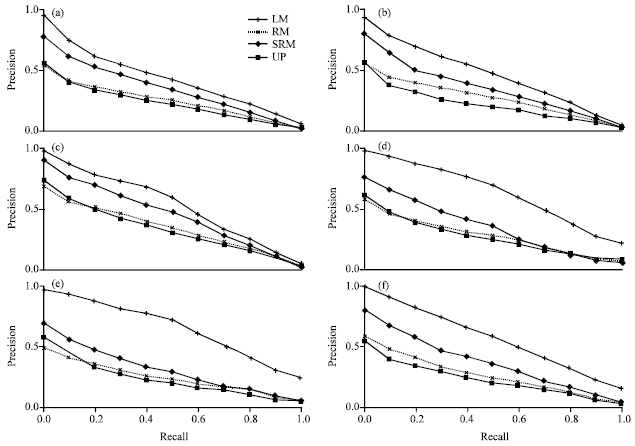 | |
| Fig. 3: | Comparison of retrieval performance in training and testing. In each plot, the RM and SRM methods are compared with the basic language model. (a) Training on AP collection, queries 51-150, (b) test on AP collection, queries 151-200, (c) test on WSJ collection, queries 151-200, (d) test on FT collection, queries 301-400, (e) test on LA collection, queries 301-400 and (f) test on SJMN collection, queries 51-150 |
| Table 5: | Comparison of topic distance |
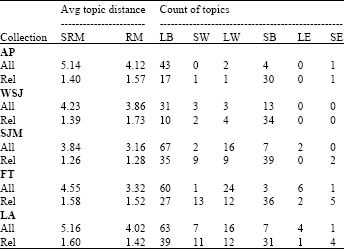 | |
We observed that TopicSRM had larger average topic distance to Collall than TopicRM (for example, 5.14 vs. 4.12 on AP collection), which indicated that our expansion terms were far from random topic than that of TopicRM.
Meanwhile, TopicSRM had smaller average topic distance to Collrel than TopicRM on collection AP, WSJ and SJMN (1.40 vs. 1.57, 1.39 vs. 1.73 and 1.26 vs. 1.28), which indicated that our expansion terms were closer to the true topic than that of TopicRM. This demonstrated that the feedback documents selected by our method were closer to the true relevance documents. This implied that TopicSRM should get better performance on AP, WSJ and SJMN collections than TopicRM and the results in Fig. 3 were consistent with this prediction. However, TopicSRM obtained larger average topic distance to Collrel on FT and LA collections than TopicRM (1.58 vs. 1.52 and 1.60 vs. 1.42). Although, this was different from what we obtained from other collections, it was consistent with the results shown in Fig. 3. That is, the performance of SRM on the FT collection had no improvement when recall was above 0.6 and the performance of SRM on the LA collection showed less improvement over RM than those on other collections.
We also observed certain correlation relationship between the topic distance and MAP. For example, our results showed that when examining the distance to random topic Collall on AP collection, the results from 43 topics (86% of total 50 topics, the summation of columns LB and SW) were consistent with the correlation between the topic distance and MAP, but that of 7 topics (14% of total 50 topics, summation of columns LW, SB and SE) were not. From other collections such as WSJ, SJMN, FT and LA collections, the percentages of correlated topics were 68, 73.4, 70.53 and 71.4%, respectively. If examining the distance to Collrel on the five collections: AP, WSJ, SJMN, FT and LA, the percentages of the correlated topics (the summation of columns LW and SB) were: 62, 76, 51, 50.5, 33.7%, respectively. Here, we saw that the LA collection was a problematic collection with only 33.7% correlation rate.
RESULTS AND DISCUSSION
Retrieval performance: Present experiments showed positive retrieval results of our SRM method. Table 3 and Fig. 3 show that our SRM method works better than LM and RM at low recall and high precision side in all cases, which makes our semantic clustering based relevance model an attractive choice in high precision applications. This indicates that many of documents in our semantic cluster are relevant to the query. We analyzed the performance improvement may be contributed by the difference between the SRM method and the RM method: (1) RM method that using all the top-ranked initial retrieved documents as feedback documents will inevitably add non-relevant documents to the estimation process of the relevance model. Our SRM method benefited from the topic separation capability of ICA which tries to group relevance documents into same semantic cluster, (2) RM method estimated relevance model based only on document models whereas SRM method took the semantic cluster information into consideration by estimating semantic models that will indicate how a document was generated from a semantic cluster model, (3) RM method viewed each document equal role in relevance model estimation whereas SRM method differentiated the contribution of each document to the estimation of relevance model, referred to Eq. 13. (4) RM method just used a collection model to smooth the document model, but it’s not optimal to estimate a probability distribution of an unseen term in a document by using the same collection model. SRM used the semantic keywords cluster along with the collection model to smooth the document model and the semantic keywords can enhance the modeling of a document that is related to the semantic topic.
However, Fig. 3 also shows that when high recall (e.g., larger than 0.7) is needed, our method, like other methods in comparison, brought much noise in the feedback so that the precision of the results dropped fast. Besides of the problem of parameter tuning, a better ICA algorithm that can better group the documents in latent semantic space may be required.
Comparing with other cluster-based retrieval method, Table 4 shows that SRM method has better retrieval performance over the other three methods. We think the main reason comes from the different clustering methods: (1) SRM method grouped documents semantically in a latent semantic space that will bring semantic information into estimation of relevance model, like the document prior probability and the semantic keywords for a cluster. But other cluster based methods can utilize such kinds of semantic information from cluster, (2) other cluster based methods smoothed the language model by counting an unseen term in a cluster and using a collection model for smoothing. Although comparing to the traditional smoothing methods, these methods used a cluster to smooth in addition, there is no topic-related semantic information to employ. SRM method used the probability of a term belonging to a semantic cluster, referred to Eq. 14 and 19 and (3) other cluster based methods treated a cluster as a large document model, SRM treated a cluster as a semantic model that is responsible for the documents and terms generation.
Although, SRM had obtained significant improvements over other methods, there is still a large gap to its upper bound and the difference is still statistical significant (Table 3, 4 and Fig. 3). This tells us two important messages: (1), our semantic clustering method, although had demonstrated its effectiveness, still either missed true relevance documents or selected non-relevant documents during the feedback process; (2), the significant better performance of the upper bound over SRM demonstrates that there is still a large room for further improvement by SRM method if we concentrate on better selection of topic-related documents.
Topic distance: Topic distance experiment showed the topic estimated from our SRM method generally has closer distance to the true topic and larger distance to the collection random topic. That indicates that our SRM method captures true relevant documents for feedback, whereas RM method which directly used all top-ranked retrieved documents as relevance feedback documents brings much noise into feedback.
The SRM obtained larger average topic distances to the true topic on FT and LA collections than RM did. It explained that the performance of SRM on the FT and LA collections has less improvement over RM than that on the other collections, especially in the case of high recall. We think that may be caused by: (1) the relevant documents per topic in FT and LA collections are the lowest among the five collections. Less relevant documents would make search topics difficult and thus make PRF less effective and (2) training feedback parameters cannot fit all different collections well.
Although, the topic distance of SRM to the true topic was larger than that of RM, SRM still showed the significant performance improvement over the RM method. We think that it is because the feedback documents of SRM method were chosen from the activation process of user’s query, which could filter out noise document from top ranked initial retrieval documents by semantic cluster information. The semantic information actually helped to form document models that are closer to the query model. For example, the document prior probability can contribute differently to the document model and the keywords of semantic cluster can keep feedback topic from random non-relevant topics, but corresponding information lacks in the RM method.
CONCLUSIONS
By viewing a document as an interaction of a set of independent hidden topics, we proposed a semantic clustering technique using independent component analysis and applied the semantic topic clusters selected by a query activation process to estimate a relevance language model without requiring relevance training information.
Based on the positive experiment results on five different TREC collections, we can draw the following conclusions. (1) it is helpful to use semantic clustering to cure the topic drifting problem in PRF, (2) estimating a document language model from documents belonging to activated semantic clusters is more effective than estimating blindly from all top-ranked retrieved documents and (3) our semantic clustering based relevance language model is a valid and robust method for PRF and we think that the main contribution of the retrieval improvement comes from the estimation of relevance model on the semantic cluster that is most similar to the query.
There are further directions to improve our semantic clustering based relevance model, (1) a more stable number estimation of independent components in data, which can reveal the real topic structure in data, should be focused on, (2) intuitively, the prior probability of a semantic cluster could play a positive role in the relevance model estimation because it differentiates the semantic importance of each semantic cluster and (3) we want to design a model estimation process with less or no parameters tuning and expect such a model would come closer to the upper-bound performance.
ACKNOWLEDGMENTS
This study was partially supported by China Scholarship Council, the University of Pittsburgh and NSF under Grant NSF/IIS 0704628.
REFERENCES
- Amari, S.I., 1998. Natural gradient works efficiently in learning. Neural Comput., 10: 251-276.
CrossRefDirect Link - Deerwester, S., S.T. Umais, G.W. Furnas, T.K. Landauer and R. Harshman, 1990. Indexing by latent semantic analysis. J. Soc. Inform. Sci., 41: 391-407.
Direct Link - Efthimiadis, E.N., 2000. Interactive query expansion: a user-based evaluation in a relevance feedback environment. J. Am. Soc. Inform. Sci. Technol., 51: 989-1003.
Direct Link - Hansen, L.K., J. Larsen and T. Kolenda, 2001. Blind detection of independent dynamic components. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, May 7-11, Salt Lake City, Utah, USA., pp: 3197-3200.
CrossRef - Hyvarinen, A., 1999. Survey on independent component analysis. Neural Comput. Surv., 2: 94-128.
Direct Link - Lafferty, J. and C. Zhai, 2001. Document language models, query models and risk minimization for information retrieval. Proceedings of the 24th ACM SIGIR Conference on Research and Development in Information Retrieval, September 9-13, 2001, New Orleans, LA, USA., pp: 111-119.
CrossRef - Lavrenko, V. and W.B. Croft, 2001. Relevance-based language models. Proceedings of the 24th ACM SIGIR Conference on Research and Development in Information Retrieval, Sept. 9-13, New Orleans, LA, USA., pp: 120-127.
CrossRef - Lee, K.S., W.B. Croft and J. Allan, 2008. A cluster-based resampling method for pseudo-relevance feedback. Proceedings of the 31th ACM SIGIR Conference on Research and Development in Information Retrieval, Jul. 20-24, Singapore, pp: 235-242.
CrossRef - Ponte, J.M. and W.B. Croft, 1998. A language modeling approach to information retrieval. Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, August 24-28, 1998, Melbourne, Australia, pp: 275-281.
CrossRefDirect Link - Sakai, T., T. Manabe and M. Koyama, 2005. Flexible pseudo relevance feedback via selective sampling. ACM Trans. Asian Language Inform. Proc., 4: 111-135.
Direct Link - Wang, X., H. Fang and C. Zhai, 2008. A study of methods for negative relevance feedback. Proceedings of the 31th ACM SIGIR Conference on Research and Development in Information Retrieval, Jul. 20-24, Singapore, pp: 219-226.
CrossRef - Wei, X. and W.B. Croft, 2006. LDA-based document models for ad-hoc retrieval. Proceedings of the 29th ACM SIGIR Conference on Research and Development in Information Retrieval, (CRDIR'06), Seattle, WA., pp: 178-185.
CrossRef - Zhai, C., 2008. Statistical language models for information retrieval: A critical review. Found. Trends Inform. Retrieval, 2: 137-213.
CrossRef - Zhai, C. and J. Lafferty, 2001. Model-based feedback in the language modeling approach to information retrieval. Proceedings of the 10th International Conference on Information and Knowledge Management, October 5-10, 2001, ACM, New York, USA., pp: 403-410.
CrossRef