
Wang Hong-xu
College of Science and Engineering, Qiongzhou University, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 4 | Page No.: 554-556







ABSTRACT
Given a transforming formula from the single value data to vague data. And presented a similarity measure formula between vague sets. In choosing location of tailings dam, the detailed steps of the VO algorithm are that: (1) Establish an index set; (2) Screen out the locations of tailings dam; (3) Draw an expectation location of tailings dam; (4) Get into vague environment. The original data turn the vague data. Get vague sets of the locations of tailings dam and vague set of a expectation location of tailings dam; (5) Calculate similarity measures. Calculate similarity measures between vague sets of the locations of tailings dam and vague set of a expectation location of tailings dam; (6) Vague optimize sort. By the numerical size of the similarity measures can be the sorts. Vague sort: similarity measures corresponding to those in greatest numerical size that is the best a location of tailings dam. The application example shows that this algorithm and these formulas are useful.
PDF Abstract XML References Citation
Received: October 28, 2011;
Accepted: November 01, 2011;
Published: January 20, 2012
How to cite this article
Wang Hong-xu, 2012. VO Algorithm and It’s an Application for the Locations of Tailings Dam. Information Technology Journal, 11: 554-556.
DOI: 10.3923/itj.2012.554.556
URL: https://scialert.net/abstract/?doi=itj.2012.554.556
DOI: 10.3923/itj.2012.554.556
URL: https://scialert.net/abstract/?doi=itj.2012.554.556
INTRODUCTION
By application GIS and fuzzy optimization theory a problem of the choosing location of tailings dam get better effect by application GIS and fuzzy optimization theory study a problem of the choosing location of tailings (Tan et al., 2009). But, calculation is more complex. And vague set theory (Gau and Buehrer, 1993) is one of popularizes of fuzzy set theory (Zadeh, 1965) and is one of best new theory that research and handle fuzzy information, too. Therefore hope apply vague set theory and discuss an identical question in the essay.
TRANSFORMING FORMULAS THE ORIGINAL DATA TO VAGUE DATA
It is key conditions that the original data transform to vague data in the application of vague set theory. Application examples in this article need a transforming formula from a single valued data into the vague data.
Definition 1: Let X = {x1, x2,..., xn} is a universe of discourse, the data of index xj (j = 1, 2, ..., n) of sets. Pi (i = 1, 2, ..., m)on X are the single valued data xij (≥0). And definite that.
Vague rule: 0≤tij ≤1-fij≤1;
Profit rule: When the xkj>xhj≥0, xkj, xhj, respectively, into the vague data as Pk (xj) = xkj = [tkj, 1-fkj], Ph (xj) = xhj = [thj, 1-fhj], the meet tkj≥thj, 1-fkj≥1-fhj. If a single valued data xij (≥0) transform to a vague data xij = [tij, 1-fij] satisfies vague rule and profit rule, then refer to this formula as profit type transforming formula.
Cost rule: When the xkj>xhj≥0, xkj, xhj, respectively, into the vague data as Pk (xj) = xkj = [tkj, 1-fkj], Ph (xj) = xhj = [thj, 1-fhj], the meet tkj≤thj, 1-fhj. If a single valued data xij = (≥0) transform to a vague data Pi (xj) = xij = [tij, 1-fij]. Satisfies vague rule and cost rule, then refer to this formula as cost type transforming formula.
Note: When the index value takes "bigger is better", the appropriate make use of profit type transformation formula; and when the index value takes "the smaller the better", the appropriate make use of cost type transforming formula.
Theorem 1: Let:
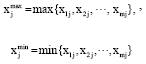 |
(i = 1, 2, ..., m; j = 1, 2, ..., n). Then
| • | Expression (1) is a profit type transforming formula: |
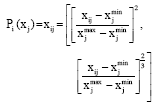 | (1) |
| • | Expression (2) is a cost type transforming formula: |
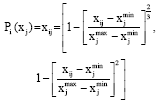 | (2) |
THE VO ALGORITHM
Promotion (Wang, 2010a-c) gives the Vague sets integrated decision-making rules, get the VO (Vague optimize ) algorithm. In choosing location of tailings dam, the detailed steps of vague optimize algorithm are that: (1) Establish an index set; (2) Screen out the locations of tailings dam; (3) Draw an expectation location of tailings dam; (4) Get into vague environment. The original data turn the vague data. Get vague sets of the locations of tailings dam and vague set of an expectation location of tailings dam; (5) Calculate similarity measures. Calculate similarity measures between vague sets of the locations of tailings dam and vague set of an expectation location of tailings dam; (6) Vague optimize sort. By the numerical size of the similarity measures can be the sorts. Vague sort: similarity measures corresponding to those in greatest numerical size that is the best a location of tailings dam.
MEASURE SIMILARITY
Definition 2: Hua-Wen and Hengyang, 2004: A vague data mining is: Let vague as:
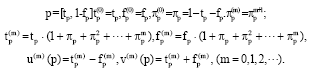 |
Definition 3 (Wang, 2010a-c): Let vague value as p = [tp, 1-fp], r = [tr, 1-fr] said formula M (p, r) is sim-ilarities measures between vague values p and r, if the M (p, r) satisfy at least the following rule:
| • | 0-1 rule 0≤M (p, r)≤1 |
| • | Symmetric rule M (p, r) = M (r, p) |
| • | Reflexive rule M (p, p) = 1 |
| • | Minimum rule If the when p = [0, 0] |
| • | r = [1, 1]or p = [1, 1], r = [0, 0] there is M (b, c) = 0, always |
Theorem 2: The following formula is the similarity measure between vague values p = [tp, 1-fp] and r = [tr, 1-fr]:
| (3) |
Copy definition 3 can be given to the definition of similarity measures between vague sets and to the definition of the weighted similarity measure between sets, not repeat. Theorem 2 will be described below with reference to the results.
Theorem 3: Let X = {x1, x2, ..., xn} is a universe of discourse, on X there is vague sets:
note simple as:
The following formula is the similarity measure between vague sets P and R (m = 1, 2, ...):
| (4) |
Theorem 4: In such as under the assumption of theorem 3 and note the elements of xi the weight for the wi ∈ [0, 1] and ![]() = 1, the following formula is a weighted similarity measures between vague sets P and R (m = 0, 1, 2, ...):
= 1, the following formula is a weighted similarity measures between vague sets P and R (m = 0, 1, 2, ...):
APPLICATION
The vague optimize algorithm used to study literature (Tan et al., 2009) the issue under discussion.
Application: The VO algorithm used to study literature (Tan et al., 2009) the issue under discussion.
Establish an index set: Take up an index set as X = {x1, x2, x3, x4, x5}, of them indexes: x1 as a maximum capacity (104 m3); x2 as a heap dam height (104 m3); x3 as area (104 m3); p4 as transmission distance (104 m3); x5 as the Dam volume (104 m3).
Screen out the locations of tailings dam: Screen out the location sets of tailings dam as P = {P1, P2, P3, P4}, where P1 is the plan 1; P2 is the plan 2; P3 is the plan 3; P4 is the plan 4. The original data of the plans as shown Table 1.
| Table 1: | Indexes data of scheme infiuence factors(basic) |
 | |
| Table 2: | The index data of the various plans (vague) |
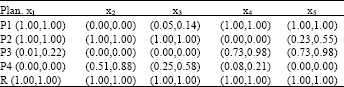 | |
Draw an expectation location of tailings dam: In this problem, the demands of an expectation location of tailings dam are that an index xi take up bigger is better and other indexes take up the smaller the better. According as these demands get the data of an expectation location of tailings dam also as shown in Table 1.
Get into vague environment: To the data of Table 1 application formula (1) calculate index x1, application formula (2) calculate other indexes, as shown in Table 2. By Table 2, get that the vague sets of the location of tailings dam and a vague set of an expectation location of tailings dam, also.
Calculate similarity measures and vague optimize sort: Application formula (4) (takem = 2) calculate similarity measures between vague sets P1, P2, P3, P4 and the results are follows:
According as the big or small of the similarity measure values can be getting following order of the plans: plan 2, plan 1, plan 3, plan 4.
Or also get the best plan for plan 2. However, Tan et al. (2009) applied GIS and fuzzy optimization theory to study the problem, need to use fuzzy matrix calculation, the calculation process more cumbersome. This algorithm is convenient and simple.
CONCLUSION
The uses of the VO algorithm are now in the ascendant. The formulas of an original data transform to vague data and formula of the similarity measure between vague sets are tow bases for the VO algorithm. Also, tow technology sustains of the VO algorithm. The application example shows that the VO algorithm also provides a new method those issues like the similar to problem.
REFERENCES
- Tan, Q.W., G.Z. Yin and Y.F. He, 2009. Application of GIS and fuzzy optimization theory to location of tailings dam. J. Nat. Disasters, 18: 110-114.
Direct Link