
Riyad Alshalabi
Yarmouk University, Irbid, Jordan
Information Technology Journal
Year: 2005 | Volume: 4 | Issue: 1 | Page No.: 38-43







ABSTRACT
This study provides a technique for extracting the triliteral Arabic root for an unvocalized Arabic corpus. It provides an efficient way to remove suffixes and prefixes from the inflected words. Then it matches the resulting word with the available patterns to find the suitable one and then extracts the three letters of the root by removing all infixes in that pattern. This technique does not use any dictionary to check the resulting stem. We define some rules that help to decide if the letters belong to the root or not. This algorithm has been tested on a corpus of 72 abstracts (10582 words) from the Saudi Arabian National Computer Conference, the accuracy of this algorithm is about 92%.
PDF Abstract XML References Citation
How to cite this article
Riyad Alshalabi, 2005. Pattern-based Stemmer for Finding Arabic Roots. Information Technology Journal, 4: 38-43.
DOI: 10.3923/itj.2005.38.43
URL: https://scialert.net/abstract/?doi=itj.2005.38.43
DOI: 10.3923/itj.2005.38.43
URL: https://scialert.net/abstract/?doi=itj.2005.38.43
INTRODUCTION
The Arabic language is a highly inflected language, this increases the difficulty of the stemming process[1]. Our methodology depends on reducing the inflected word by removing all its suffixes and prefixes according to a certain methodology. When this process is done correctly; it becomes easy to find the pattern that matches this word and extract the stem characters (Fig. 1). Aljlayl and Frieder[1] used this idea to develop a light stemmer for information retrieval applications. Here we used this general idea but with a different technique.
Removing all suffixes and prefixes from the word helps in reducing the number of patterns. It facilities the pattern matching process and enables more variations of the stem to be conflated to the same pattern[2,3].
Arabic stemming: Arabic words demonstrate an intricate morphology[4]. The Arabic language can be said to use root-and-pattern morphotactics where a pattern can be thought of as a template adhering to established grammatical rules.
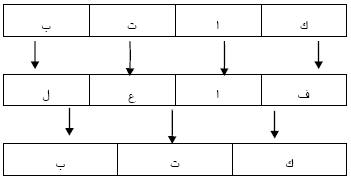 | |
| Fig. 1: | Extracting the stem of the word |
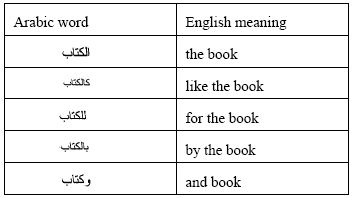 | |
| Fig. 2: | Some prefixes attached to the word book |
Such patterns are applied by adding affixes (prefixes, infixes or suffixes) to roots (which are simple bare verbs that are three letters in length) to form their parent root. Prefixes and suffixes can be further added to Arabic stems to express common grammatical usages such as the possessives, plurals, definite forms, gender, etc[4]. For example, some of the additional forms of the word (![]() ) “book” are shown in Fig. 2 Many characters are attached to the word (
) “book” are shown in Fig. 2 Many characters are attached to the word (![]() ) while in English these additions appear as separate forms.
) while in English these additions appear as separate forms.
Stemming can be defined as the process of normalizing word variations by removing prefixes and suffixes to get the affix free word[5]. There are four kinds of stemmers[6]:
| 1. | Manually constructed dictionaries: These are easy to use tables listing the roots and stems of words. The only problem with these is that they may not be exhaustive[6]. |
| 2. | Light stemmers: These remove suffixes and prefixes to discover the original stem and group words with the same parent stem. They are usually referred to as stem-based stemmers[7]. |
| 3. | Morphological analyzers: These algorithms attempt to restore the original root of a word and group words accordingly[8]. These are known as root-based stemmers and are far more complex than light stemmers. Because such stemmers group terms based on their roots, terms that are not semantically related may also be grouped into an equivalence class. |
| 4. | Statistical stemmers: These stemmers attempt to group word variants using clustering techniques[9]. The different techniques vary from using letter N-gram based retrieval to using co-occurrence analysis. This process essentially involves a process of repartitioning and regrouping terms into new classes to correct the errors from earlier stemming stages. A unique advantage that statistical stemmers enjoy is that they are somewhat more language independent. |
Algorithm description: In our algorithm, we have the following steps:
| Step 1: | Normalize corpus |
| Step 2: | Remove the determiner |
| Step 3: | Check for prefixes with duplicate letters and remove the first one. |
| Step 4: | IF the first letter is |
| • | Remove all suffixes. |
| • | IF CheckPrefix( |
| ELSE IF the first letter is | |
| • | Remove all suffixes. |
| • | IF CheckPrefix( |
| Step 5: | IF the first letter is |
| • | Remove all suffixes. |
| • | IF CheckPrefix( |
| Step 6: | Reduce the word |
| • | Remove non single letter prefixes. |
| • | Remove all suffixes. |
| • | Remove single letter prefixes ( |
| Step 7: | Match with pattern. |
| • | IF no match then return the original word and EXIT. |
| Step 8: | Normalize root. |
Normalizing the corpus: The corpus is normalized as follows:
| 1. | Convert the first letter of the word |
| 2. | Remove vowels (except the Shaddah symbol |
| 3. | Duplicate any letter that has the Shaddah symbol. |
| 4. | Remove punctuation. |
| 5. | Remove stop words. |
Removing stop words: Before finding the stem of any word, we check if the word is a stop word or not. To do this we use a list that contains most of the Arabic stop words.
Removing the deeterminer ![]() : The second step in the algorithm is to remove the determiner
: The second step in the algorithm is to remove the determiner ![]() and its combinations (Fig. 3). All these characters must be removed from the word, since these letters are the leftmost prefixes that can appear in an Arabic word.
and its combinations (Fig. 3). All these characters must be removed from the word, since these letters are the leftmost prefixes that can appear in an Arabic word.
Before removing any prefix or suffix, the algorithm checks the size of the word; the number of characters
remaining word length must be greater than or equal to 3. For example, the prefix ![]() will not be removed from the word
will not be removed from the word ![]() . Some words have these same characters as root characters (e.g.
. Some words have these same characters as root characters (e.g. ![]() ,
, ![]() ). To stem such words correctly we check these patterns before removing their prefixes. Using this rule the word
). To stem such words correctly we check these patterns before removing their prefixes. Using this rule the word ![]() , for example, will be reduced to the word
, for example, will be reduced to the word ![]() , as we will explain later and then return the stem
, as we will explain later and then return the stem ![]() .
.
Removing prefixes: The next step is to remove all multiletter prefixes that have no duplicated. letters. Figure 4 shows the duplicated letters. If these letters are found then the first one is considered a prefix and will be removed. For example, the words ![]() ,
, ![]() and
and ![]() will be reduced to
will be reduced to ![]() and
and ![]() , respectively.
, respectively.
We check the multiletter prefixes shown in Fig. 5. In this step we do not check the single letter prefixes (![]() and
and ![]() ) because these characters could be root letters and not prefixes. For example, the letters
) because these characters could be root letters and not prefixes. For example, the letters ![]() and
and ![]() in the words
in the words ![]() , respectively both belong to the stem . So after removing the suffixes later, the remaining word will be retained as a stem since its length is 3.
, respectively both belong to the stem . So after removing the suffixes later, the remaining word will be retained as a stem since its length is 3.
Removing suffixes: The word must be reduced to match an appropriate pattern. When the inflected word enters this step, the algorithm checks for the suffixes shown in Fig. 6 working from the longest to the shortest one. As mentioned above, the algorithm checks the length of the word before removing any suffi; the length of the remaining word must be greater than 2.
| Fig. 3: | The determiner |
| Fig. 4: | Duplicated prefix letters |
| Fig. 5: | The most frequent multiletter prefixes |
 | |
| Fig. 6: | Most available suffixes |
For example, let’s start with the word ![]() . In step 2 the eterminer
. In step 2 the eterminer ![]() is removed, returning
is removed, returning ![]() . No prefixes are found in step 3. In step 4 the suffix
. No prefixes are found in step 3. In step 4 the suffix ![]() is removed, returning
is removed, returning ![]() .
.
As another example the word ![]() enters step 4 and its suffixes are removed starting with the longest
enters step 4 and its suffixes are removed starting with the longest ![]() then the shorter
then the shorter ![]() , finally return
, finally return ![]() as a suffix-free word.
as a suffix-free word.
Some conditions for suffix removal are illustrated later in this study.
Removing ![]() and
and ![]() : These two letters have the meaning of (then) and (and) in English respectively, so they written before any single letter prefix as
: These two letters have the meaning of (then) and (and) in English respectively, so they written before any single letter prefix as ![]() , which indicates the present form of the verb, but in Arabic they cannot be used together and still have the same meaning. So, if both of them appear, the second letter will not be a prefix. In this step we check one of them only. These letters can sometimes be root letters not prefixes, for example:
, which indicates the present form of the verb, but in Arabic they cannot be used together and still have the same meaning. So, if both of them appear, the second letter will not be a prefix. In this step we check one of them only. These letters can sometimes be root letters not prefixes, for example: ![]() etc. it is difficult to distinguish these words without using a database containing all Arabic stems. To resolve this ambiguity we use some rules that depend on patterns. If the word matches a certain pattern, then the letter will not be removed, as will be explained later.
etc. it is difficult to distinguish these words without using a database containing all Arabic stems. To resolve this ambiguity we use some rules that depend on patterns. If the word matches a certain pattern, then the letter will not be removed, as will be explained later.
Although this technique resolves this problem partially, it sometimes fails with some words, especially when two words reduce to the same string. For example, consider the pair of words ![]() and
and ![]() , the letter
, the letter ![]() is a prefix in the first word but not in the second one.
is a prefix in the first word but not in the second one.
Now in step 4 if the first letter of the inflected word is ![]() or
or ![]() , we remove all suffixes of the word. This helps us to match this word with certain patterns. If the match succeeds, then the character is considered to be a root letter and will not be removed from the beginning of the word.
, we remove all suffixes of the word. This helps us to match this word with certain patterns. If the match succeeds, then the character is considered to be a root letter and will not be removed from the beginning of the word.
Removing ![]() : These letters are not used as prefixes before the prefixes
: These letters are not used as prefixes before the prefixes ![]() or
or ![]() , so we check them in the next step (step 5). Here we use the approach illustrated above. In the next section we discuss the rules used to check these prefixes.
, so we check them in the next step (step 5). Here we use the approach illustrated above. In the next section we discuss the rules used to check these prefixes.
Reducing the inflected word: In this step the inflected word is completely stripped of all suffixes and prefixes, this is done after dealing with all previous affixes, but here more single letter prefixes are removed (![]() and
and ![]() ) if they are considered as prefixes. As we described, multiletter prefixes are removed first, then all suffixes and finally single letter prefixes. For example the word “ ” will enter directly at step 6 and will be reduced as follows:
) if they are considered as prefixes. As we described, multiletter prefixes are removed first, then all suffixes and finally single letter prefixes. For example the word “ ” will enter directly at step 6 and will be reduced as follows:
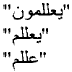 |
Pattern matching: After removing all prefixes and suffixes of the inflected word we match it with all available patterns. If a pattern is found then we can extract the letters that form the root, if no match found we return the inflected word as it is.
Patterns: We tried to reduce the number of patterns by increasing both the prefix and suffix lists. For example we do not store any of these patterns:
![]() etc. Instead, we remove all these prefixes and suffixes before matching the word with its pattern. This reduces the number of patterns and makes it easy to find the correct pattern.
etc. Instead, we remove all these prefixes and suffixes before matching the word with its pattern. This reduces the number of patterns and makes it easy to find the correct pattern.
In addition, we grouped patterns according to their length, so we have patterns of length 4 as ![]() , length 5 as
, length 5 as ![]() , length 6 as
, length 6 as ![]() . The total number of patterns with length 4 is 11, the total number of patterns with length 5 is 25 and the total number of patterns with length 6 is 15.
. The total number of patterns with length 4 is 11, the total number of patterns with length 5 is 25 and the total number of patterns with length 6 is 15.
We match any word with patterns according to its length, by using a set of conditions to check the infix letters in the word. For example, the word ![]() has length6, so we search the patterns using the following conditions:
has length6, so we search the patterns using the following conditions:
Find a pattern with length 6 that has
| • | |
| • | |
| • |
These conditions match only the pattern ![]() . Now we remove these letters and extract the stem
. Now we remove these letters and extract the stem ![]() .
.
The order of these rules and the conditions used for matching are very important factors in guaranteeing a correct matching.
Normalized roots: The final step in the algorithm is to normalize the resulting stem. For example, the stem for the word ![]() is
is ![]() , to normalize it we replace the first letter by
, to normalize it we replace the first letter by ![]() and the root becomes
and the root becomes ![]() . Another example is to convert
. Another example is to convert ![]() in the beginning of the stem to
in the beginning of the stem to ![]() . For example the inflected word
. For example the inflected word ![]() has the root
has the root ![]() . After normalization it l becomes “
. After normalization it l becomes “![]() ”.
”.
Rules for removing single letter prefixes: After removing all multiletter prefixes and all suffixes of the inflected word we match the resulting word with certain patterns. If a match is found, then we consider the checked letter as a root letter. These patterns are not the same for each prefix (as we will show).
We encountered problems with this technique, because for some words ambiguity resolution is not possible without using a database containing all Arabic stems or alternatively using a vocalized corpus. This is because both words contain the same consonant string To solve this problem we selected the most [appropriate? frequent?] usable word of the pair.
For example the pair of words ![]() and
and ![]() have the same string, the letter
have the same string, the letter ![]() is a prefix in the first word but not in the second one. Here one of them must be selected. The formal statement of the rule is: If a word that starts with
is a prefix in the first word but not in the second one. Here one of them must be selected. The formal statement of the rule is: If a word that starts with ![]() has the pattern
has the pattern ![]() then remove it, because here it is used with a verb, So, the prefix
then remove it, because here it is used with a verb, So, the prefix ![]() will be removed from any word that has the pattern
will be removed from any word that has the pattern ![]() . We used this technique with all other single letter prefixes. There are some patterns that do not have such problems, for example the pattern
. We used this technique with all other single letter prefixes. There are some patterns that do not have such problems, for example the pattern ![]() .
.
Rules for the prefix ![]()
CheckPrefix(![]() )=FALSE IF the word matches one of the following patterns:
)=FALSE IF the word matches one of the following patterns:
 |
ELSE CheckPrefix(![]() )=TRUE
)=TRUE
Rules for prefix ![]()
CheckPrefix(![]() )=FALSE IF the word matches with one of the following patterns:
)=FALSE IF the word matches with one of the following patterns:
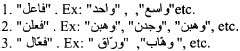 |
ELSE CheckPrefix(![]() )=TRUE
)=TRUE
Rules for prefix ![]()
CheckPrefix(![]() )=FALSE IF the word matches one of the following patterns:
)=FALSE IF the word matches one of the following patterns:
 |
ELSE CheckPrefix(![]() )=TRUE
)=TRUE
Notice that this prefix is not used with verbs, so more patterns can be used and the number of problems becomes smaller.
Rules for the prefix ![]()
We used the same patterns that are used with the prefix ![]() above. but there are some problems. For example, the word
above. but there are some problems. For example, the word ![]() is correctly reduced to
is correctly reduced to ![]() , but the word
, but the word ![]() is also reduced, which is not correct.
is also reduced, which is not correct.
Rules for the prefix ![]()
This prefix is used to talk about the future, so we add ![]() to the prefix list, of strings to be removed at the beginning of the algorithm (step 3).
to the prefix list, of strings to be removed at the beginning of the algorithm (step 3).
For example ![]() .
.
Rules for the prefix ![]()
CheckPrefix(![]() )=FALSE IF the word matches one of the following patterns:
)=FALSE IF the word matches one of the following patterns:
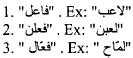 |
ELSE CheckPrefix(![]() )=TRUE
)=TRUE
Rules for the prefixes ![]()
These two letters are checked in step 5, so if the remaining stringis of length 3 then we are guaranteed that one of these two letters belongs to the root.
CheckPrefix(![]() )=FALSE IF the word matches one of the following patterns:
)=FALSE IF the word matches one of the following patterns:
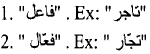 |
ELSE CheckPrefix(![]() )=TRUE
)=TRUE
Suffix removal constraints: Some suffixes cannot be removed from the inflected word, because they are considered to be part of the root, so we need to add some exceptions to the rules for removing suffixes. For example, the inflected word ![]() (according to the algorithm) will be reduced to
(according to the algorithm) will be reduced to ![]() , which is wrong, because the letter
, which is wrong, because the letter ![]() is a single letter suffix (as in
is a single letter suffix (as in ![]() ). To deal with such problems we defined some constraints on such suffixes:
). To deal with such problems we defined some constraints on such suffixes:
| 1. | Do not remove |
| 2. | Do not remove |
| 3. | Do not remove |
| 4. | Do not remove |
| 5. | Do not remove |
| 6. | Do not remove |
| 7. | Do not remove |
General problems: Problems may arise with some inflected words, since an original letter(s) may be removed or match a word with non-suitable pattern. These problems arise as a result of the similarity of strings of some words.
Examples
| 1. | Words such as the inflected word |
| 2. | The algorithm cannot distinguish between the two words |
| 3. | The pair of words |
| 4. | The pair of words |
Examples
The inflected word ![]() enters the algorithm at step 6, no multi character prefixes are found, so the suffix list will be checked and the suffix
enters the algorithm at step 6, no multi character prefixes are found, so the suffix list will be checked and the suffix ![]() will be removed, only a three letter root will remain (
will be removed, only a three letter root will remain (![]() ).
).
Also the word ![]() will enter at step 6 and the suffix removal process will start as follows
will enter at step 6 and the suffix removal process will start as follows
Then the prefix ![]() will be removed (not a root character).
will be removed (not a root character).
Now if we have the inflected word ![]() ,it will enter step 4:
,it will enter step 4:
| 1. | remove suffix as follows: |
| 2. | check( |
Enter step 5:
| 1. | Remove suffix: no match. |
| 2. | Check( |
Enter step 6: (reduce word):remove single letter prefix.
Enter step 7: match ![]() with patterns and return the root
with patterns and return the root ![]() .
.
The inflected word ![]() is stemmed as follows:
is stemmed as follows:
Enter step 6:
| 1. | Remove prefix, resulting word is |
| 2. | Remove suffixes, resulting word is |
| 3. | No single letter prefix found. |
Enter step 7: match it against the pattern ![]() and extract
and extract ![]()
Enter step 8: convert ![]() .
.
Another example, the inflected word ![]()
Enter step 2: remove ![]()
Enter step 6 as follows:
 |
 |
CONCLUSIONS
Morphological analysis is the first step in most natural language processing applications. We have developed a new algorithm that runs an order of magnitude faster than other algorithms in the literature. This study provides an efficient technique for extracting the triliteral root for an unvocalized Arabic corpus. This technique does not depend on searching, since we do not store any Arabic stems. It depends on suffix removal, prefix removal and pattern matching. The algorithm has been implemented using Visual Basic 6.0. We tested our algorithm using a corpus of 72 abstracts (10582 words) from the Saudi Arabian National Computer Conference., The algorithm performs very well and the accuracy is approximately 92%.
REFERENCES
- Aljlayl, M. and O. Frieder, 2002. On arabic search: Improving the retrieval effectiveness via a light stemming approach. Proceedings of the ACM Conference on Information and Knowledge Management, (CKM'I02), McLean, Virginia, USA., pp: 340-347.
Direct Link - Rogati, M., S. McCarley and Y. Yang, 2003. Unsupervised learning of arabic stemming using a parallel corpus. Proceedings of the Association for Computational Linguistics, Sapporo, Japan, Jul. 07-12, Association for Computational Linguistics Morristown, New Jersey, USA., pp: 391-398.
CrossRefDirect Link