
Jinchao Guo
5 Dongfeng Road, Zhengzhou, 450002, China
Gang Hu
5 Dongfeng Road, Zhengzhou, 450002, China
Hongying Wang
5 Dongfeng Road, Zhengzhou, 450002, China
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 6 | Page No.: 1215-1221







ABSTRACT
This study presents an Immune Agent Networks (IAN) control model. Based on this model, a behavioral control paradigm is developed. Effective coordination and mutual understanding between agents can be achieved by adopting such a behavioral control based on their corresponding behavior. Each agent is abstracted as an independent entity that searches for environment and exhibits robust behavior to accomplish tasks. In this article, simulations are presented with a box-collecting system. The significance of the behavioral control paradigm and the impact of the IAN-based behaviors on the overall performance of the box-collecting system are examined. We furthermore try to evolve affinities among antibodies using testing method. The simulation results validate the efficiency of the proposed IAN model and the importance of paratope mapping evolving is pointed out and related optimization methods that can be used to evolving the paratope mapping are illustrated.
PDF Abstract XML References Citation
Received: December 31, 2010;
Accepted: March 01, 2011;
Published: May 13, 2011
How to cite this article
Jinchao Guo, Gang Hu and Hongying Wang, 2011. Ian-Based Cooperative Control Model for Multi-agent System. Information Technology Journal, 10: 1215-1221.
DOI: 10.3923/itj.2011.1215.1221
URL: https://scialert.net/abstract/?doi=itj.2011.1215.1221
DOI: 10.3923/itj.2011.1215.1221
URL: https://scialert.net/abstract/?doi=itj.2011.1215.1221
INTRODUCTION
The roots of biological metaphors are deeply embedded in the biological study of self-organized behaviors in social insects and other natural biological interaction process (Garnier et al., 2007). A new emerging biological metaphor that adopts the characteristics of the immune system is called Artificial Immune System (AIS). AIS exhibits the properties of human immune system for performing complicated tasks, for example, computing network security (Harmer et al., 2002), scheduling (Ge et al., 2008), data mining (Freitas and Timmis, 2007), autonomous robotics (Ishiguro et al., 1995; Whitbrook et al., 2007, 2010), medical diagnostic systems (Polat and Gunes, 2007) to multi-object optimization (Chen et al., 2010; Wong et al., 2009) and others.
The highly distributed and adaptive properties of the AIS are adopted to develop the control model that has the ability to organize, coordinate and schedule a group of agents in a closed scenario, such as garbage collection, moving supplies through factories and mail delivery. Hence, an intelligent multi-agent, self-organizing and self-learning system that is robust to achieve goals independently can be derived. Lau et al. (2009) designed a cooperative control model for multi agent-based material handling systems from the perspective of clone characters of AIS and made simulation in Matlab. Ishiguro et al. (1995) made dynamic behavior arbitration of autonomous mobile robots based on network characters of AIS and the results was optimized using GA algorithm, however, the majority of its action selections are built on fuzzy set theory.
Based on network characters of AIS, Jerne and Cocteau (1984) proposed a remarkable hypothesis: idiotypic network hypothesis. Under Jerne’s Immune Networks theory, a more sophisticated control model: Immune Agent Networks (IAN) control model was proposed in this study. The proposed control model addresses how individual agent with unique behaviors or talents can be exploited through communication and cooperation with each other in achieving goals. Agents are able to determine various kinds of responses by perception of the changing environment and interact mutually through recognition, stimulation and suppression.
PRELIMINARIES
Biological immune system: The natural biological immune system is a distributed novel-pattern detection system with several functional components positioned in strategic locations throughout the body. The immune system regulates defense mechanism of the body by means of innate and acquired immune responses. Innate immunity is inborn and unchanging. It provides resistance to a variety of antigens during their first exposure to a human body. Innate immunity therefore operates non-specifically during the early phase of an immune response. This general defense mechanism is known as primary immune response which is slower and less protective. In addition to providing the early defense against infectious, innate immunity enhances acquired immunity against the infectious agents which is known as the secondary immune response (Lau et al., 2009). On reoccurrence of the same antigens, a much faster and stronger secondary immune response is resulted. The ability of adaptive immunity to mount more rapid and effective responses to repeat encounters with the same antigen is achieved by the mechanism of immunological memory where immune cells proliferate and differentiate into memory cells during clonal expansion (Cadavid, 2003).
Jerne’s immune networks theory: On the basis of network characters of AIS, Jerne proposed the famous idiographic immune network theory which makes it possible to describe immune system from mathematics perspective and this prompts immunology into a really subject from experiments directly. In immune network theory, every cell is not in isolated state. They interact through recognition, stimulation and suppression and thus homeostasis is achieved via a chemical dynamic network system by the interaction of a number of cell types. Invasion by pathogens triggers a perturbation to the homeostasis which results in the classical immune response.
For the sake of convenience in the following explanation, we furthermore introduce several terminologies in immunology. The portion on the antigen recognized by the antibody is called epitope (antigen determinant) and the one on the antibody that recognizes the corresponding antigen determinant is called paratope. Recent studies on immunology have clarified that each type of antibody has also its specific antigen determinant called idiotope (Ishiguro et al., 1995). The simplified working procedure of immune network is schematically illustrated in Fig. 1. In essence, the immune system is controlled by the action of a large number of regulatory and effector molecules. They have various cell surface receptors and soluble molecules such as interleukins that can transmit signals between immune cells to eliminate foreign antigens. Antibody (mainly generated by B cell) has paratope and idiotope on their surface which can be used to identify antigens and self-recognition. When antigens invade into body, the equilibrium state of immune system is perturbed. Epitope of the antigen is recognized by the Paratope (P2) of cell B2, so anti-body generated by cell B2 is stimulated, at the same time, Idiotope (Id2) of the antibody generated by cell B2 is recognized by Paratope (P1) of the antibody generated by cell B1, so, antibody generated by cell B2 is suppressed. On the other hand, antibody 3 generated by cell B3 stimulates antibody 2 since the idiotope Id3 of antibody 3 works as an antigen viewed from Cell B2.
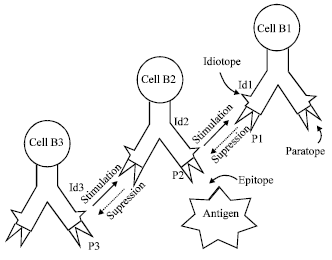 | |
| Fig. 1: | A general structure of immune network |
In this way these stimulation and suppression chains among antibodies form a large-scaled chain loop and works as a self and not-self recognizer. Again, the heart of Jerne's idea is that the self-nonself recognition in the immune system is carried out at system level. According to the immune network theory proposed by Jerne and Cocteau (1984) and Farmer et al. (1986) gives out a general equation group which can be used to calculate antibody’s concentration.
AIS-BASED COOPERATIVE CONTROL MODEL
Ian-based control framework: In Jerne’s immune network theory, antibody produced to foreign antigen elicits an anti-idiotypic antibody that acts to control further production of anti-idiotypic antibody. The immune system is therefore kept in balance without the presence of antigens and the return to equilibrium is represented by an immune response. This balancing mechanism of antibody leads to an important concept of automatic control of antibody concentration that stimulates or suppresses an immune response. Based on Jerne’s theory, a control framework which can be used to design multi-agents system is proposed. Figure 2 schematically shows the immune agent network system (IAN). As shown in Fig. 2, each agent contains a set of fundamental capabilities in the default stage. The basic actions an agent performs include exploring the surrounding environment and communicating with each other. When agent detects antigens, i.e. the specified task, it will take actions and select the corresponding antibody according to the binding affinity. Binding affinity is determined by the interaction between antibodies and environment. According to the complexity of tasks, the system will choose one or several agents to accomplish task, solve problems and keep homeostasis, meanwhile, useful information will be recorded into memory lib via communication and used for the secondary response that occurs upon second and subsequent exposure to an antigen.
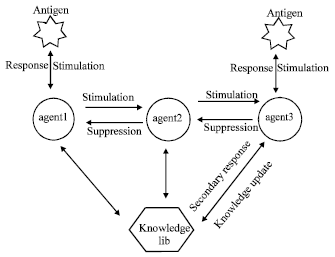 | |
| Fig. 2: | Structure of the proposed immune multi-agent network system |
The secondary response is characterized by more rapid kinetics and greater magnitude relative to the primary response that occurs upon the first exposure.
Control schedule: The control framework proposed in this paper adopts the biological theory of human immune system for manipulating agents’ internal behaviors. Agents are able to provide different responses from its perception of the environment. There is no centralized control or initial plan that dictates the Agents which tasks they should first complete. Agents use the measure of binding affinity to recognize and approach tasks. The binding affinity g is quantified by the distance between an agent and a specified task. When a task is recognized by an agent, it will then manipu-late its capabilities to tackle the task. This manipulation of capability allows agents to perform appropriate responses and actions to complete the task with maximum efficiency and in minimal time. Binding affinity is formally defined as follows:
| (1) |
where, the star denotes multiplication, ![]() is the binding affinity used by agent i to recognize task k, Bi is agent i’s capability to deal with a given task and dij is the Euclidean distance measured between a task and an agent and can be computed as follows:
is the binding affinity used by agent i to recognize task k, Bi is agent i’s capability to deal with a given task and dij is the Euclidean distance measured between a task and an agent and can be computed as follows:
| (2) |
where, (xi, yi) and (xj, yj) are Cartesian coordinate pairs of agent i and task j.
In collaboration mode, when an agent is waiting for help with a task, the binding affinity will be consolidated to obtain the required help. The waiting agents will work as sources for consolidated stimulation signals and attract other agents coming to help based on the self-tuning.
According to Eq. 1, the consolidated stimulation values between antibodies and antigens will be calculated as:
| (3) |
where, ω is a variant, Aw is the number of waiting agents for the same task, bj is the capability of agent i and f is an incremental function of bj..
From Eq. 3, we can see that the more waiting agents there are and the more capabilities agents have, the more stimulation values agent i will have to cope with task k.
When an agent selects a task, it has the chance to be selected by other agents. Therefore, for the task, each agent generated antibodies, respectively. According to IAN framework, Stimulations and suppressions coexist between antibodies. The interaction between antibodies will be calculated as:
| (4) |
where, bi and bj are the capabilities of agent i and j to cope with tasks, dij is the distance between the two agent i and j.
In Eq. 4, the sign of rij varies according to stimulation and suppression, respectively. If the interaction is stimulation, rij takes positive and vice-versa.
Based on Fasher’s dynamic equations, a simplified equation can be derived:
| (5) |
| (6) |
where, i, j, k, gik, ki , α and β all have the same meanings as the ones in Fasher’s dynamic equations. is corresponding to mij in Fasher’s dynamic equations.
Strategic behavioral control for agents: In a multi-agent system, teamwork is an important and frequently occurred activity. Here, teamwork means when two or more agents work cooperatively to achieve a common goal. When a group of agents are working together, a crucial aspect is to have understanding and agreement among agents through communication. Hence, the behavior of agents which is characterized by unique behavior states, is studied to project their correct operation strategies. Through these behavioral states, an agent is able to determine its behavior in conjunction with the state information of other cooperating agents obtained via communication; thereby an overall strategic plan is developed based on the mutual understanding between agents. Agents alter their behaviors by monitoring the dynamic environment. In different stages of an operation cycle, Agents change their behavior states to perform different activities according to different antibodies they have chosen. Figure 3 shows the behavior model of an agent given in the form of a state transition diagram that defines the change of behavior of an agent in response to help and request for help in operation.
According to Jerne’s network theory, the group behavior of agents is regulated by the agents’ concentration in response to a particular task. A concentration level is given to every task in the default stage. The higher is the task concentration level, the larger is the number of agents needed to complete the job. Initially, it is assumed that all agents are in the wandering state searching for task when they are deployed in a workplace. Once a task has been found by a particular agent, it changes its behavioral state to the task locking state which is companied by color changing from red to yellow and approaches the task. While the agent is approaching the targeted task, the concentration level of that task is being checked. If the task concentration is greater than unity, the agent will send signal to request for help and change to the idle state until there are enough agents to complete the task, then their colors will turn into green. Agents who receive signals from the requesting agent will reply to the request and only agents in the wandering state will respond to the request and change their states from wandering to cooperation state. Agents that are stimulated by and have triggered responses towards other tasks are not able to participate in another teamwork operation. On the other hand, if there are enough number of agents responded to the same cooperative task, other agents who are approaching to that task but in a further location will leave this task and change the behavioral state back to the explore state and look for new tasks.
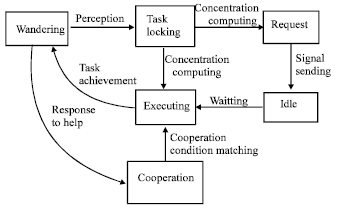 | |
| Fig. 3: | The state transition diagram of an agent |
| Table 1: | Strategies corresponding to an agent’s behavioral states |
 | |
Six different behavior states have been planned to characterize different antibodies that are taken by an agent under different operating conditions, as is listed in Table 1.
Environmental situations were modeled as antigens and responses to them were modeled as antibodies in the simulation. An Antibody class was designed to interface with the controller and each may belong to one or two states, so that multiple antibody objects could be created. The class had public double attributes strength, concentration and activation and a public double array paratope-strength to hold the degree of match (a value between 0 and 1) for each antigen. There was also a public integer array idiotope-match to hold disallowed mappings (a value of 1 for a disallowance, 0 otherwise) between the antibody and each antigen and thus represent the idiotypic suppression and stimulation between anti- bodies. The behaviour of the robot in response to environmental conditions was hence analogous to external matching between antibodies and antigens and internal matching between antibodies.
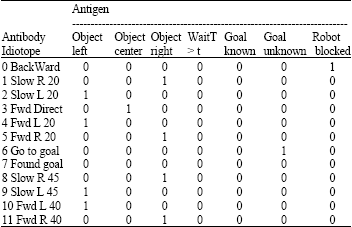
The degrees of paratope matching were initially hand designed. They were allowed to change dynamically through reinforcement learning. Table 2 shows the 7 antigens and 12 antibodies that were selected and the match values that were initially assigned.
| Table 2: | Paratope match mappings between antibodies and antigens |
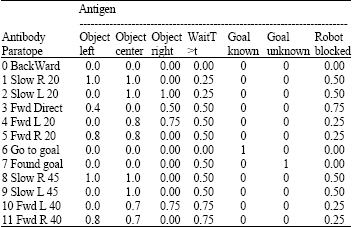 | |
| L and R donate left and right, respectively | |
| Table 3: | Idiotope match mappings between antibodies and antigens |
 | |
| L and R donate left and right, respectively | |
The idiotope mappings were also designed by hand, but were not developed in any way. Table 3 shows the idiotope values used.
It is worth noting that although the initial idiotope matrix was not developed in any way, the idiotypic results were still adaptive. The presence of suppressive and stimulatory forces was based on the static idiotope matrix but the scores awarded or deducted for these effects were taken from the dynamic paratope matrix.
SIMULATION STUDY
Simulation description: To evaluate the reliability and the efficiency of the AIS-based control framework, a box collecting study for multi-agent construction are performed. We implement this case study using Player/Stage. Player and Stage run on many UNIX-like platforms are released as Free Software under the GNU General Public License (Gerkey et al., 2003). Player provides interfaces to the robot’s sensors and actuators over network and provides communication between the robots of the system. Additionally, PLAYER provides a layer of hardware abstraction that permits algorithms to be tested in simulated 2D and 3D environments (STAGE and GAZEBO, respectively) and on hardware.
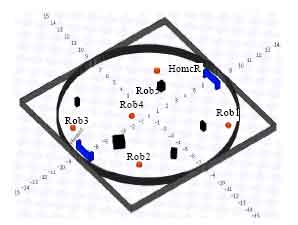 | |
| Fig. 4: | An illustration of the layout of simulated arena |
Stage provides a two-dimensional bitmapped environment where robots and sensors operate. The devices all can be accessed through Player, as if they were real hardware. Stage aims to be efficient and configurable rather than highly accurate. In present simulation, a square workplace is constructed. It’s assumed that the boxes have different weight but has uniform presentation shape-a square box and randomly located in workspace. All agents are initially placed randomly among the workplace. Two “home” depots where boxes will be stored are located at the middle of the right and left edges of the workplace. The layout of the simulated arena is depicted in Fig. 4.
The AIS-based control paradigm is fully distributed where no supervisors or leaders are defined. AIS agents are allowed to move freely within the workplace and they have the ability to obtain information about the environment within their sensory range while they are exploring the environment and exchange information with other agents that are in close proximity defined by the communication range. Tasks defined in this study require either a single agent or a group of agents to handle, mainly depending on agent’s capability and the special task it has locked. The main objective of this case study is to demonstrate how coordination enhances the overall efficiency of a multi-agent system based on the AIS-based paradigm. In view of this, the explicit handling of tasks is not within the scope of this study and the execution of these tasks is therefore not considered. Nonetheless, the complexities of these tasks are crucial for agents in making their decisions. Their corresponding complexity chains by which their corresponding complexity chains by which specificity matching and binding affinity between tasks and agents are evaluated evaluate specificity matching and binding affinity between tasks and agents represent such complexities that represent different types of tasks.
| Table 4: | The parameter of box weight and robot ability |
 | |
Experiment setup: A simulation is said to be completed when agents have accomplished all the tasks in the workplace. As initiating agents will become idle when they are waiting for help and in the case when the number of tasks is greater than the number of agents, a deadlock is resulted when all the agents have attached to different tasks and waiting for help. As such, a condition is imposed to limit the idling time for initiating agents, i.e., an initiating agent will evoke stimulation signals and wait for assistance within a fixed period of time. After that, if no one has replied to the signals, the initiating agent will abandon the cooperative task and search for other tasks. In this case study, the duration of idling time is set to 10 time steps.
During simulation, a special box collecting scenario was considered here: there are a lot of boxes randomly scattered in the arena. A swarm of agents (herein, the number of agent is 5) are searching and retrieving boxes back to “homes” which is nearer from them. Each box has different weight and each robot has different executive ability. The parameters are used in simulation are listed in Table 4. Based on the environmental information obtained by onboard sensors, robots can detect a target and lock a task which can be seen from the simulation results.
Case studies show, the coordination and performance of the AIS-based control framework is satisfactory which also are validated by the results.
ANALYSIS AND CONCLUSION
As indicated above, the degrees of paratope matching were initially hand designed. It implied that the simulation results should not be optimal. We update the paratope table just according to the testing results obtained during simulation. This process can be replaced by other algorithm such as: GA (Genetic Algorithm), PSO (Particle Swarm Optimiz ation Algorithm), ACO (Ant Colony Optimization) etc.
Figure 5 indicates Robot (agent) 5 has found a box and it can’t move the box by itself, so it sends a signal and waiting for help.
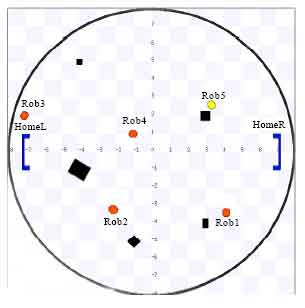 | |
| Fig. 5: | Screenshot 1: Agent 5 finding a target and waiting for help to move its target |
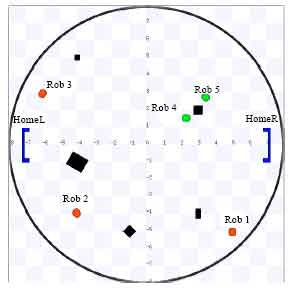 | |
| Fig. 6: | Screenshot 2: Agent 4 informed and cooperating with agent 5 to take the task |
The “white” color denotes Robot 5 being in Request state. In Fig. 6, Robot 4 receives the signal and joins in Robot 5 successfully. The “grey” color indicates that they have passed the concentration level testing. In Fig. 7, Robot 4 and 5 cooperate together to move their object box to homeR which is more near to them. Meanwhile, Robot 2 and Robot 3 have locked the same task but they can’t reach the concentration level demanded and their color means they are waiting for help.
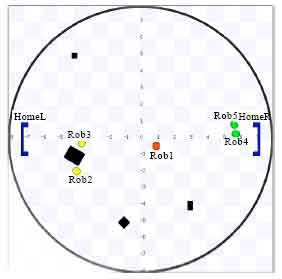 | |
| Fig. 7: | Screenshot 3: agent 4 and 5 cooperate together to move box to home. Meanwhile, agent 2 and 3 have locked the same task but they can’t reach the concentration level demanded and their “white” color means they are waiting for help. For the sake of simplicity, during the cooperation of agent 4 and 5, their box is moved out of the simulation |
ACKNOWLEDGMENTS
The authors would like to thank Prof Guangzhao Cui and Doc. Yanfeng Wang who work in Key Lab of Information based Electrical Appliances of Henan Province. Thanks for their kindness and help in instrument and workspace provision. Many experiments are executed in the key lab. This work is supported by the Natural Science Foundation of Henan Province of China under grant No. 092300410036.
REFERENCES
- Garnier, S., J. Gautrais and G. Theraulaz, 2007. The biological principles of swarm intelligence. Swarm Intell., 1: 3-31.
CrossRef - Harmer, P.K., P.D. Williams, G.H. Gunsch and G.B. Lamont, 2002. An artificial immune system architecture for computer security applications. IEEE Trans. Evol. Comput., 6: 252-280.
Direct Link - Ge, H.W., L. Sun, Y.C. Liang and F. Qian, 2008. An effective PSO and AIS-based hybrid intelligent algorithm for job-shop scheduling. IEEE Trans. Man Cybernetics, 38: 358-368.
CrossRef - Ishiguro, A., T. Kondo, Y. Watanabe and Y. Uchikawa, 1995. Dynamic behavior arbitration of autonomous mobile robots using immune networks. Proc. IEEE Int. Conf. Evol. Comput., 2: 722-727.
CrossRef - Whitbrook, A.M., U. Aickelin and J.M. Garibaldi, 2007. Idiotypic immune networks in mobile-robot control. IEEE Trans. Syst. Man Cybernetics, 37: 1581-1598.
CrossRef - Whitbrook, A.M., U. Aickelin and J.M. Garibaldi, 2010. Two-timescale learning using idiotypic behaviour mediation for a navigating mobile robot. Applied Soft Comput., 10: 876-887.
CrossRef - Polat, K. and S. Gunes, 2007. Medical decision support system based on Artificial Immune Recognition Immune System (AIRS), fuzzy weighted pre-processing and feature selection. Expert Syst. Appl., 33: 484-490.
CrossRef - Chen, J., Q. Lin and Z. Ji, 2010. A hybrid immune multi-objective optimization algorithm. Eur. J. Operat. Res., 204: 294-302.
Direct Link - Wong, E.Y.C., H.S.C. Yeung and H.Y.K. Lau, 2009. Immunity-based hybrid evolutionary algorithm for multi-objective optimization in global container repositioning. Eng. Appl. Artificial Intell., 22: 842-854.
CrossRef - Lau, H.Y.K., V.W.K. Wong and A.K.S. Ng, 2009. A cooperative control model for multiagent-based material handling systems. Expert Syst. Appl., 36: 233-247.
CrossRef - Jerne, N.K. and J. Cocteau, 1984. Idiotypic networks and other preconceived ideas. Immunol. Rev., 79: 5-24.
CrossRef - Farmer, J.D., N.H. Packard and A.S. Perelson, 1986. The immune system, adaptation and machine learning. Physica D: Nonlinear Phenomena, 22: 187-204.
CrossRefDirect Link - Freitas, A.A. and J. Timmis, 2007. Revisiting the foundations of artificial immune systems for data mining. IEEE Trans. Evol. Comput., 11: 521-540.
CrossRef